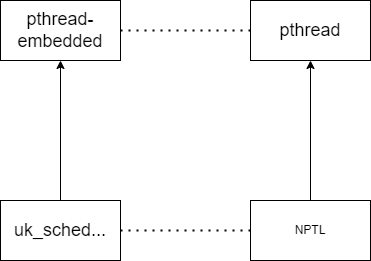
Linux线程模型
Linux线程的发展
多线程最早由LinuxThreads带入Linux,但是LinuxThread不符合POSIX的的标准,因此NPTL(Native POSIX Thread Library)产生。NPTL采用了一对一的线程模型,符合了POSIX多线程标准,在稳定性和性能方面都有了很大的提升。NPTL在Linux 2.6版本中被引入。
在Linux中可以使用以下命令查看 线程库的实现方式
1 | libos@ubuntu:~$ getconf GNU_LIBPTHREAD_VERSION |
NPTL的实现
NPTL的解决方法与LinuxThread类似,内核看到的首要抽象依旧是一个进程,新线程是通过引入Clone()系统调用产生的,clone是Linux独有的,任何其他UNIX系统的版本中都没有CLone函数。clone()的引入了模糊了线程与进程的区别。clone()的函数原型如下所示。
1 | int clone(int (*fn)(void *), void *child_stack, int flags, void *arg); |
- fn: fn是对于的函数指针,创建的线程的函数入口
- child_stack: 线程的堆栈中指针
- flags: 创建线程的标志
- arg: 传递给子线程的参数
调用该函数可以在当前进程或者新的进程中创建一个线程,具体依赖于参数flags。如果在当前进程中创建新线程,新创建的线程将与其他存在的线程共享地址空间,任何一个线程对于地址空间做出修改对于同一进程中的其他线程都是可见的。
flags是一个位图,每一位可以单独设置,决定了新创建的线程与父线程共享的内容。
| 标志 | 置位时的含义 | 清除时的含义 |
|---|---|---|
| CLONE_VM | 创建一个新线程 | 创建一个新进程 |
| CLONE_FS | 共享umask、根目录和工作目录,调用进程或者子进程对chroot、chdir、umask的调用会影响其他进程 | 不共享 |
| CLONE_FILES | 共享文件描述符 | 复制文件描述符 |
| CLONE_SIGHAND | 共享信号处理程序表 | 复制该表 |
| CLONE_PARENT | 新线程与调用者有相同的父亲 | 新线程的父亲是调用者 |
更多细节可以参考以下Linux Clone
pthread是POSIX Threads的一套API协议,而NPTL是该协议的具体实现。NPTL采用1:1的线程模型,每一个用户态的线程在内核都有与之对应的内核级线程。
Linux线程的定义
在Linux中,用一个叫做task_struct(/usr/src/linux…/linux/sched.h)的数据结构表示所有执行的上下文。不会在内核中具体区分线程还是进程。因此线程在Linux中又被叫做轻量级进程。
在task_struct中,定义了Pid进行区分不同的进程,每一个进程或者线程都拥有自己的pid,同时pid也是task_struct结构体的唯一标志。同时对于一个进程下的几个线程,尽管它们拥有不同的pid,到但是它们的tgid都是一样的,指向自己所属进程的pid。
可以理解成在Linux中,线程使用进程模拟出来的。
线程与进程的创建过程
如果Linux采用进程模拟线程的方法,那么我们就需要关注一下二者创建的过程。
在linux内核版本6.0.1中,fork系统调用最终返回的是kernel_clone的结果
1 | SYSCALL_DEFINE0(fork) |
在kernel_clone中,一个比较关键的函数是copy_process。在该函数中会实现各类资源的初始化,通过传递过来的参数选择是共享还是重新分配。
1 | pid_t kernel_clone(struct kernel_clone_args *args) |
此时我们测试一个案例,使用strace跟踪其系统调用过程。
1 | clone(child_stack=NULL, flags=CLONE_CHILD_CLEARTID|CLONE_CHILD_SETTID|SIGCHLD, child_tidptr=0x7f930b5af790) = 1081 |
可以看到,fork函数最终也会调用到clone函数。
回到线程,查看pthread中关于pthread_create的源码,使用strace跟踪可以看到,pthread_create使用的系统调用也是clone函数
1 | clone(child_stack=0x7fcce4369fb0, flags=CLONE_VM|CLONE_FS|CLONE_FILES|CLONE_SIGHAND|CLONE_THREAD|CLONE_SYSVSEM|CLONE_SETTLS|CLONE_PARENT_SETTID|CLONE_CHILD_CLEARTID, parent_tidptr=0x7fcce436a9d0, tls=0x7fcce436a700, child_tidptr=0x7fcce436a9d0) = 31082 |
检查clone系统调用可以看到,clone和fork最终都是调用kernel_clone实现的
1 | SYSCALL_DEFINE5(clone, unsigned long, clone_flags, unsigned long, newsp, |
以上说明,对于Linux而言,线程与进程在内核中是没有很大的区别的。线程与进程在内核里均用task_struct表示。
二者的具体区别通过跟踪可以看到,仅仅是传入clone系统调用的参数不同。
| 线程创建时的参数 | 含义 |
|---|---|
| CLONE_VM | 创建一个线程 |
| CLONE_FS | 共享umask、根目录和工作目录 |
| CLONE_FILES | 共享文件描述符 |
| CLONE_SIGHAND | 共享信号处理程序表 |
| CLONE_THREAD | 单元格 |
| CLONE_SYSVSEM | 共享System V信号量 |
| CLONE_SETTLS | 创建TLS |
| CLONE_PARENT_SETTID | 在父进程中保存子进程的ID |
| CLONE_CHILD_CLEARTID | 子进程终止时,清空保存的ID |
线程调度
Linux的调度是基于内核线程的。Linux目前采用的调度器为CFS(Complete Fair Scheduler),提出该调度器是为了解决先前O1调度器存在的问题。
CFS的主要思想是采用一颗红黑树作为调度队列的数据结构,根据task在CPU上运行时间的长短而有序排列,这种时间被称为虚拟运行时间(vruntime)。vruntime根据一定的公式计算而出。运行时间更短的会分布在树的左侧,左侧的任务会优先被调度。CFS算法的基本原理就是,优先调度使用CPU时间少的任务,同时增加虚拟运行时间。
同时考虑到任务存在优先级,CFS会根据对应任务的优先级,改变其虚拟运行时间流逝的速度。优先级越低,时间流逝速度越快,因此虚拟时间增加的越快。因此优先级较高的任务,虚拟运行时间提升较慢,反而更加容易被调度。
一旦vruntime的次序发生变化,则系统会开始尝试进行调度。但是如果队列中的大部分任务的vruntime的时间都非常接近,此时进行调度,则调度频率会非常高。解决这个问题,又引入了一个阈值,如果前后两个线程的vruntime保持在阈值内,则不会触发调度。
但是CFS只考虑可运行的任务,对于阻塞中的任务,会存放于等待队列中。
更加具体的内容可以参考Linux CFS调度器
与unikraft对比
由于unikraft是一个单进程的操作系统,与Linux相比,精简了很多。但是在对线程的生命周期管理上的一些操作是非常相似的。
其次,unikraft也算是内核级线程,通过pthread-embedded创建的线程在内核中会有一个uk_thread与之对应,这点也与Linux相似。
但是unikraft明确定义了线程结构体,而Linux是统一使用了一个叫做task_struct的结构体,模糊了线程和进程的区别。二者在细节上有所不同,但是结构上非常类似。
我认为unikraft的线程模型或多或少都有借鉴Linux线程模型。同时Linux的线程调度这段会比unikraft更加复杂,unikraft就是简单的FIFO调度算法。