1 | sudo qemu-system-x86_64 -fsdev local,id=myid,path=$(pwd)/fs0,security_model=none \ |
处理器虚拟化技术 (豆瓣) (douban.com)
QEMU/KVM源码解析与应用 (豆瓣) (douban.com)
总体I/O流程
Virtio and Vhost Architecture - Part 1 | Better Tomorrow with Computer Science (insujang.github.io)
虚拟化
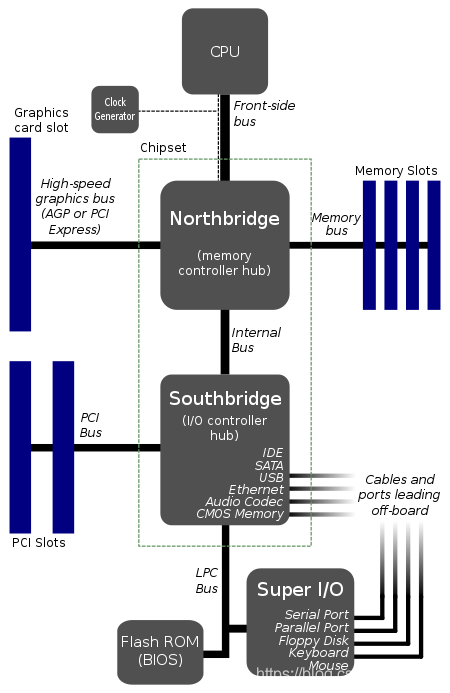
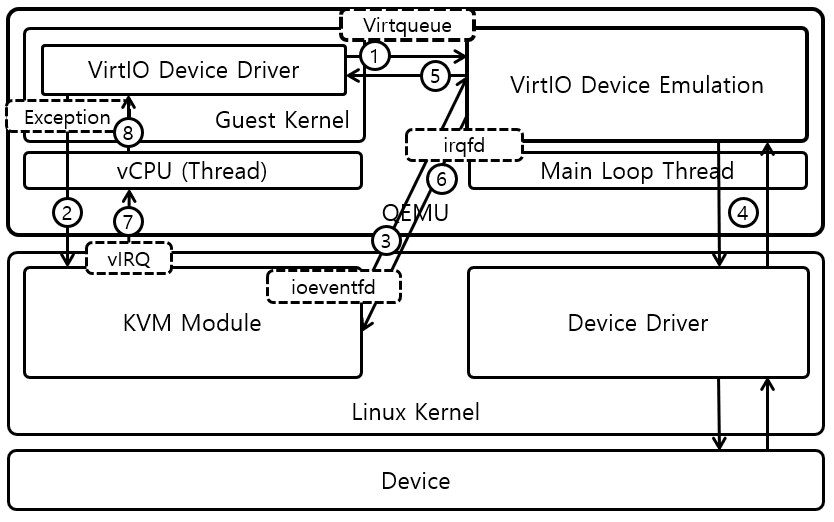
virtio是一种前后端架构,包括前端驱动(Front-End Driver)和后端设备(Back-End Device)以及自身定义的传输协议。通过传输协议,virtio不仅可以用于QEMU/KVM方案,也可以用于其他的虚拟化方案。如虚拟机可以不必是QEMU,也可以是其他类型的虚拟机,后端不一定要在QEMU中实现,也可以在内核中实现(这实际上就是vhost方案)。
前端驱动为虚拟机内部的virtio模拟设备对应的驱动,每一种前端设备都需要有对应的驱动才能正常运行。前端驱动的主要作用是接收用户态的请求,然后按照传输协议将这些请求进行封装,再写I/O端口,发送一个通知到QEMU的后端设备。后端设备则是在QEMU中,用来接收前端驱动发过来的I/O请求,然后从接收的数据中按照传输协议的格式进行解析,对于网卡等需要实际物理设备交互的请求,后端驱动会对物理设备进行操作,从而完成请求,并且会通过中断机制通知前端驱动。
virtio前端和后端驱动的数据传输通过virtio队列(virtqueue)完成,一个设备会注册若干个virtio队列,每个队列负责处理不同的数据传输,有的是控制层面的队列,有的是数据层面的队列。virtqueue是通过vring实现的。vring是虚拟机和QEMU之间共享的一段环形缓冲区。当虚拟机需要发送请求到QEMU的时候就准备好数据,将数据描述放到vring中,写一个I/O端口,然后QEMU就能够从vring中读取数据信息,进而从内存中读出数据。QEMU完成请求之后,也将数据结构存放在vring中,前端驱动也就可以从vring中得到数据。
PCI虚拟化
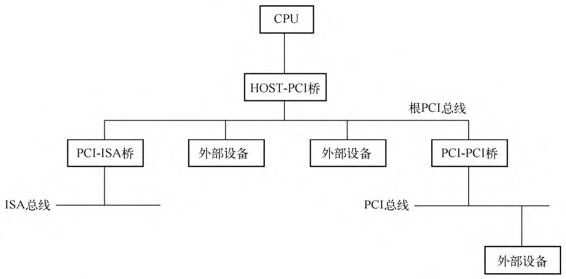
PCI设备有自己独立的地址空间,叫作PCI地址空间,也就是说从设备角度看到的地址跟CPU角度看到的地址本质上不在一个地址空间,这种隔离就是由图中的HOST-PCI主桥完成的。CPU需要通过主桥才能访问PCI设备,而PCI设备也需要通过主桥才能访问主存储器。主桥的一个重要作用就是将处理器访问的存储器地址转换为PCI总线地址。x86架构对于存储器地址空间和PCI地址空间不是很清晰,因为本质上是两个不同的地址空间,但是其地址是相同且一一对应的。
每个PCI设备都有一个配置空间,该空间至少有256字节,其中前面64个字节是标准化的,每个设备都是这个格式,后面的数据则由设备决定。
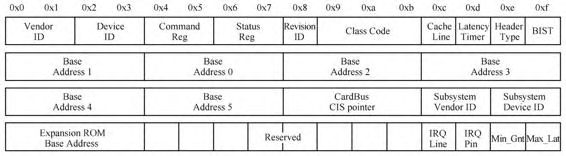
Vendor ID、Device ID、Class Code用来表明设备的身份,有的时候还会设置Subsystem Vendor ID Subsystem Device ID。6个Base Address表示的是PCI设备的IO地址空间,虚拟机可以通过这些地址空间对设备进行读写配置控制,除了6个BAR,还可能有一个ROM的BAR。有两个与中断设置有关的值,IRQ Line表示设备使用哪一个中断号,如传统的中断控制器由两个82599芯片级联而成,有0到15号Line,IRQ Line表示的是用哪一根线,IRQ Pin表示的是PCI设备使用哪一条引脚连接中断控制器,PCI总线上的设备可以通过4根中断引脚INTA~D#向中断控制器提交中断请求,这里的IRQ Pin即用来表示这个引脚编号,1~4分别表示INTA~INTD的4个引脚,大部分设备使用中断线INTA引脚,如果设备不支持中断,则该域为0。
PCI总线能够发送对应的INTA~INTD 4个信号,这4个信号会与中断控制器的IRQ_PIN引脚相连。PCI总线规范中并没有规定PCI设备的INTx信号与中断控制引脚的相连关系,因此系统软件需要使用中断路由表存放PCI设备的INTx信号与中断控制器的连接关系,中断路由表通常是由BIOS等系统软件建立的。
操作系统与PCI设备交互的主要方式是PIO和MMIO,MMIO虽然是一段内存,但是其没有EPT映射,在虚拟机中访问设备的MMIO时,会产生VM Exit,KVM识别此MMIO访问并且将该访问分派到应用层QEMU中,QEMU根据内存虚拟化的步骤进行分派,找到设备注册的MMIO读写回调函数,设备的MMIO读写回调函数根据设备的功能进行模拟,完成模拟之后可能会发送中断到虚拟机中,从而完成一些MMIO访问。
北桥的PCI部分有两个I/O寄存器,其中一个是配置地址寄存器,叫作CONFGADDR,该寄存器的作用是选择PCI设备。北桥的PCI部分的另一个寄存器是配置数据寄存器,叫作CONFGDATA,这个寄存器用来对CONFGADDR中指定的设备进行配置。CONFADDR使用从端口0xcf8开始的4个端口,CONFDATA使用从0xcfc开始的4个端口。
1 | // unikraft::plat/common/include/pci/pci_bus.h |
写CONFGADDR的行为会设置配置寄存器的值(outl, outb…),指定选择的PCI设备,用于随后的数据访问。
virtio设备首先需要创建一个PCI设备,叫作virtio PCI代理设备,这个代理设备挂到PCI总线上,接着virtio代理设备再创建一条virtio总线,这样virtio设备就可以挂到这条总线上了。
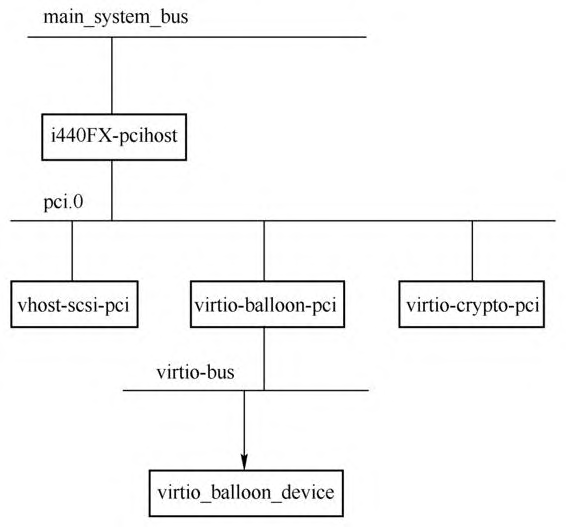
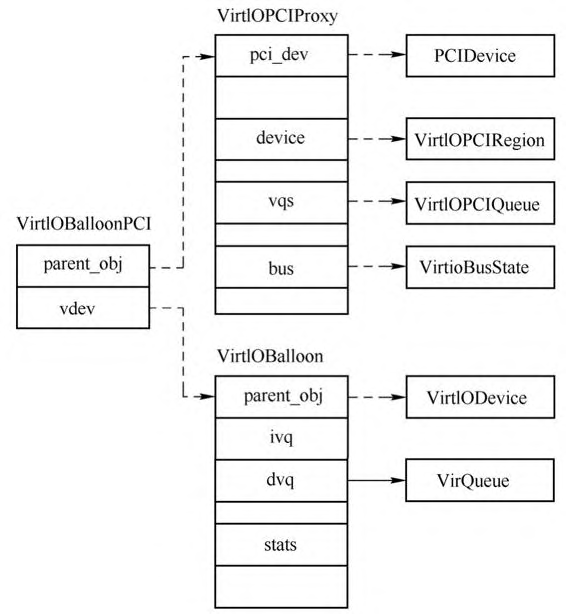
上图显示了virtio balloon设备对应的几个数据结构,VirtIOBalloonPCI是virtio balloon PCI代理设备的实例对象,其包括两个部分:一个是VirtIOPCIProxy,这个是virtio PCI代理设备的通用结构,里面存放了具体virtio PCI代理设备的相关成员;另一个是VirtIOBalloon,这个结构里面存放的是virtio balloon设备的相关数据,其第一个成员是VirtIODevice,也就是virtio公共设备的实例对象,VirtIOBalloon剩下的成员是与virtio balloon设备相关的数据。
在使用9p挂载qemu启动的时候命令行有一句参数-device virtio-9p-pci进行具现化,设备的具现化函数都会调用device_set_realized函数,在该函数中会调用设备类的realize函数。最开始调用的是DeviceClass的realize函数,这个回调的默认函数是device_realize,当然,如果继承自DeviceClass的类可以重写这个函数,如PCIDeviceClass类就在其类初始化函数pci_device_class_init中将DeviceClass->realize重写为pci_qdev_realize,对于PCIDeviceClass本身来说,其PCIDeviceClass->realize可设置为pci_default_realize,后面继承PCIDeviceClass的类可以在自己的类初始化函数中设置realize函数。例如9p设备通过virtio_9p_pci_class_init()进行具现化。
1 | // qemu::hw/virtio/virtio-9p-pci.c 注册了9p-pci设备挂到pci总线上,这个设备专门用来挂9p设备 |
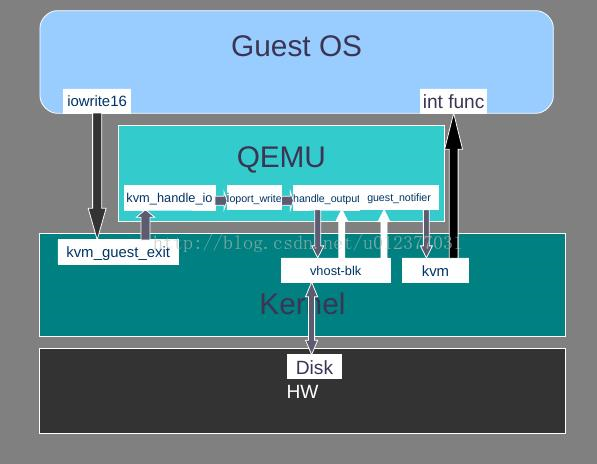
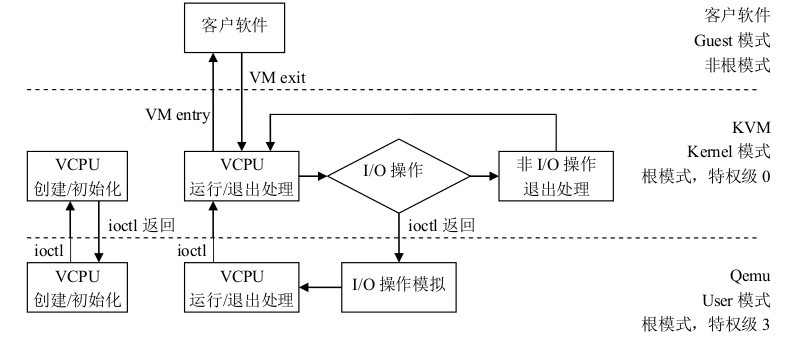
对于设备模拟,虚拟机通过触发VM Exit退出到KVM,接着由KVM或者QEMU完成I/O模拟等操作。当KVM或QEMU完成了I/O请求或者有其他事件需要通知虚拟机时,则通过注入中断的方式让虚拟机得到事件通知。从I/O请求的分发路径来看,每次虚拟机内部写设备的MMIO或者PIO的时候,都会导致陷入到KVM,然后分发到QEMU,QEMU中还会进行一轮分发,这个过程比较低效,因此ioeventfd方案就应运而生了。ioeventfd主要是基于eventfd,在初始化的时候QEMU将一段I/O地址空间和一个eventfd联系起来,当虚拟机写I/O地址的时候,陷入KVM,KVM直接设置该I/O地址对应的fd,QEMU主循环返回,执行相应的函数,这样就绕过了QEMU层的分发。irqfd也是基于eventfd,当触发irqfd的fd时,会直接注入中断到虚拟机中。
一个完整的I/O流程包括从虚拟机内部到KVM,再到QEMU,并由QEMU最终进行分发这样一个同步过程,I/O完成之后的返回路径与之相反。当然,使用同步的I/O请求有其原因,如很多时候虚拟机内部需要这些I/O数据才能继续运行。但是存在这样一种情况,即I/O请求本身只是作为一个通知事件,这个事件本身可能是通知KVM或者QEMU完成另一个具体的I/O,这种情况下没有必要像普通I/O一样等待数据完全写完,而是只需要完成一个简单的通知。如果这种I/O请求也使用之前同步的方式完成,很明显会增加不必要的路径。ioeventfd就是对这种通知I/O进行的优化,用户层程序(如QEMU)可以为虚拟机特定的地址关联一个eventfd,并对该eventfd进行事件监听,然后调用ioctl(KVM_IOEVENTFD)向KVM注册这段地址,当虚拟机内部因为I/O发生VM Exit时,KVM可以判断其地址是否有对应的eventfd,如果有就直接调用eventfd_signal发送信号到对应的fd,这样,QEMU就能够从其事件监听循环返回,进而进行处理。
Intel VT-x虚拟化
Intel提供3个层面的虚拟化技术(Intel Virtualization Technology)
- 基于处理器的虚拟化技术(Intel VT-X) 全称为 Virtualization Technology for x86
- 基于PCI总线域设备实现的I/O虚拟化技术(Intel VT-D) 全称为Virtualization Technology for Directed I/O
- 基于网络的虚拟化技术(Intel VT-C) 全称为Virtualization Technology for Connectify
Intel实现了VMX架构来支持CPU端的虚拟化技术(Intel VT-x技术),引入了一种新的处理器操作模式,被称为VMX operation。也加入了一系列的VMX指令支持VMX operation模式。
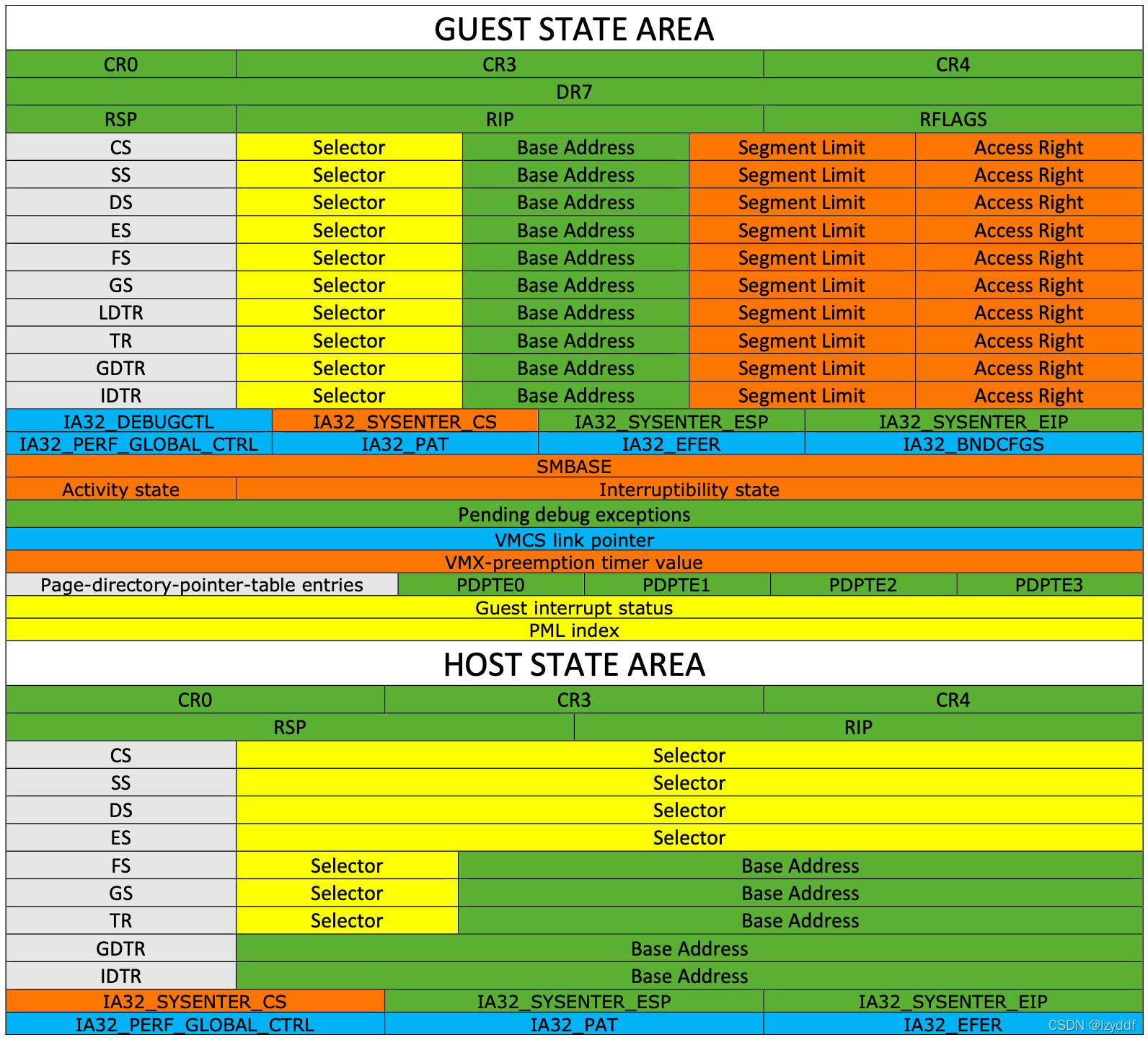
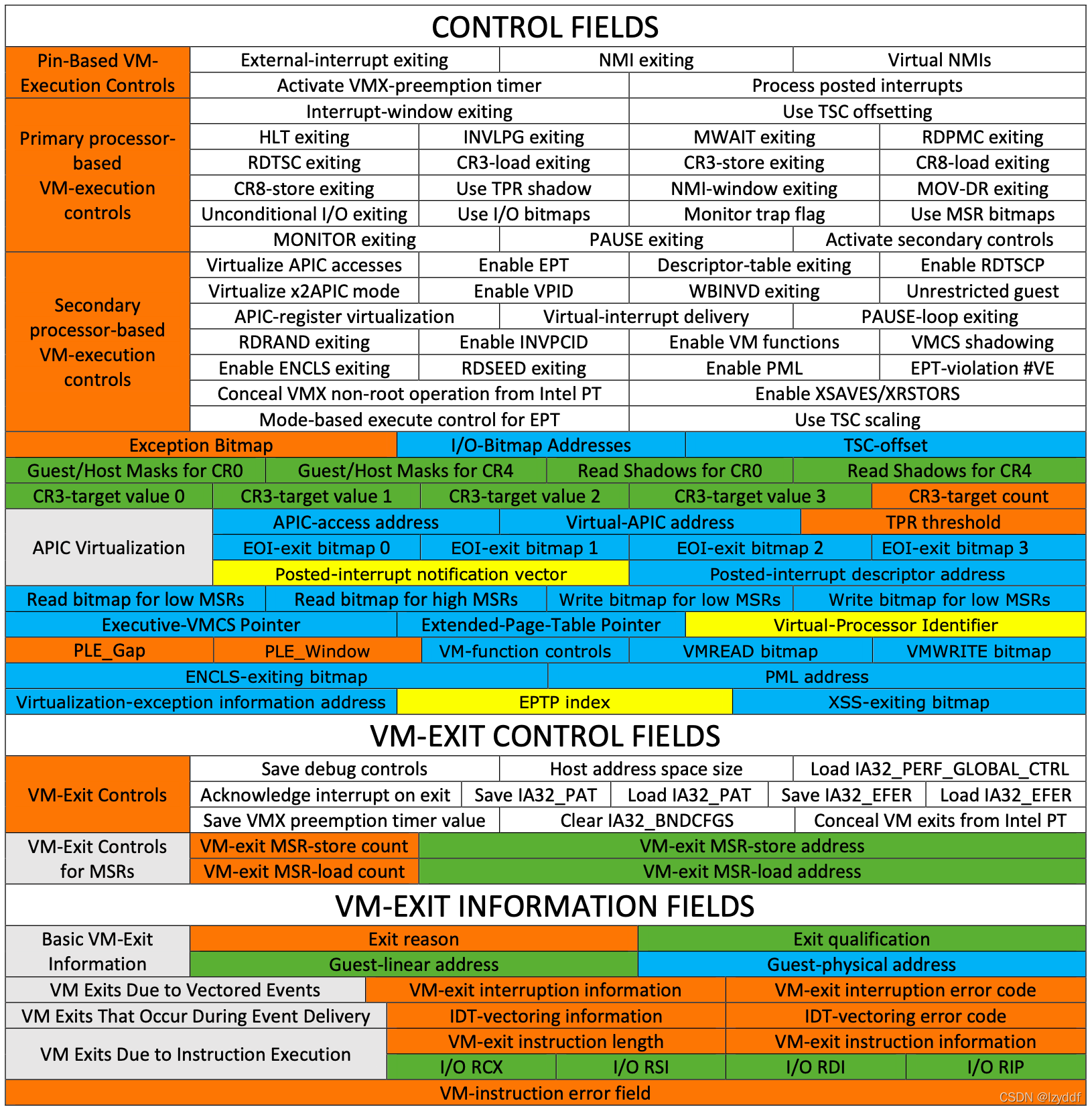
逻辑处理器在VMX操作时使用虚拟机控制数据结构(virtual-machine control data structures,VMCSs)。它们管理进入和退出VMX non-root(虚拟机入口和虚拟机出口)的过渡,以及VMX non-root中的处理器行为。这个结构由指令VMCLEAR、VMPTRLD、VMREAD和VMWRITE操作。
VMCS字段列表如下(不同版本,各字段的位置可能不同)