论文链接: https://dl.acm.org/doi/10.1145/3503222.3507732
摘要
现有的serverless computing平台是建立在同构计算机上的,限制了函数密度并且将serverless computing限制在有限的场景中。我们推出了Molecule,这是第一个使用异构计算机的无服务计算系统。Molecule实现了通用设备(如Nvidia DPU)和特定领域加速器(如FPGA和GPU),从而显著提高功能密度(高了50%)和应用程序性能(高达34.6倍)。为了实现这些结果,我们首先提出了XPU-Shim,这是一种分布式shim,用于弥合底层多操作系统(当使用通用设备时)和我们的serverless服务器运行时(即Molecule)之间的差距。我们进一步介绍了vectorized sandbox,这是一种抽象硬件异构性的sandbox抽象(当使用特定领域的加速器时)。此外,我们还回顾了关于启动和通信延迟的最先进的serverless优化,并克服了在异构计算机上实现他们的挑战。我们已经具有Nvidia DPU和Xilinx FPGA的真实平台上实现了Molecule,并使用benchmarks和真实世界的应用。
异构计算
异构计算主要是指使用不同类型指令集和体系架构的计算单元组成系统的计算方式。常见的计算单元类别包括CPU、GPU等协处理器、DSP、ASIC、FPGA 等。我们常说的并行计算正是异构计算中的重要组成部分异构计算近年来得到更多关注,主要是因为通过提升CPU时钟频率和内核数量而提高计算能力的传统方式遇到了散热和能耗瓶颈。而与此同时,GPU等专用计算单元虽然工作频率较低,具有更多的内核数和并行计算能力,总体性能/芯片面积的比和性能/功耗比都很高,却远远没有得到充分利用。
FPGA
FPGA 的全称为 Field-Programmable Gate Array,即现场可编程门阵列。 FPGA 是在 PAL、 GAL、 CPLD 等可编程器件的基础上进一步发展的产物, 是作为专用集成电路( ASIC)领域中的一种半定制电路而出现的,既解决了定制电路的不足,又克服了原有可编程器件门电路数有限的缺点。 简而言之, FPGA 就是一个可以通过编程来改变内部结构的芯片。
基本介绍
首先介绍了serverless的优点和基本概念,这点不多赘述。
然后介绍了serverless目前面临的挑战,大概分为以下几点:
- 同构计算机下的serverless功能密度低
- 现在很多程序(ML,AI之类的)依赖于异构加速器来实现加速
异构计算机极大地提高了可伸缩性(即垂直扩展)、更广泛应用程序的性能以及资源隔离。有了这些好处,近年来,异构计算机正迅速渗透到数据中心。
介绍了第一个异构计算机上的serverless computing系统Molecule,Molecule同时考虑了通用设备(如NVIDIA DPU)和特定领域加速器(如FPGA)。Molecule利用DPU实现更好的功能密度,利用FPGA实现更好的应用程序性能
但是异构计算机上的serverless目前也面临很多挑战:
- DPU和加速器本身就需要用一个专用OS去管理,这样一来异构计算机就变成了一个多OS的系统。我们如何在多操作系统系统中实现相同的功能?
- 缺少能够抽象出serverless服务器系统的低级异构硬件和软件细节
- 异构计算机也使无服务器功能之间的通信复杂化,现在的serverless系统依赖于OS原语,例如IPC,但是还是通过网络进行两个PU之间的通信
应对挑战
vectorized sandbox —-> 克服异构性挑战
vectorized sandbox扩展了现有的抽象,以支持并发sandbox创建和调用。由于我们要求每个设备 (或PU) 实现抽象所需的接口,因此无服务器运行时可以管理异构功能,而无需考虑底层的硬件和软件细节。
XPU-Shim ——-> 弥合serverless机制与多OS系统之间的差距
提出了两个原语:neighbor IPC与distributed capabilities
neighbor IPC利用硬件互联,例如DMA,以允许不同的PU上的应用程序有效地通信,而distributed capabilities提供了一种统一的方式在multi-os系统中实施权限控制。
Motivation
讲的都是一些技术背景,这里不多赘述
关键抽象
XPU-Shim
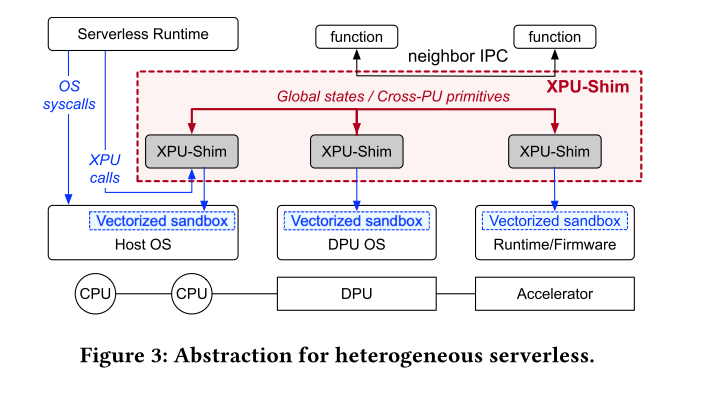
XPU-Shim的三个特点:
- XPU-Shim 在每个 PU(称为本地操作系统)的操作系统或固件上工作,并利用矢量化沙箱的接口来管理异构功能,这显着提高了系统灵活性,因为本地操作系统和 PU 可能非常不同
- XPU-Shim 为应用程序提供系统调用风格的接口,称为 XPUcalls,它提供统一的抽象来管理和利用不同 PU 上的资源。
- XPU-Shim 即使在不同的 PU 上也支持应用程序的高效通信。 XPU-Shim 依赖于两个关键原语,distributed capabilities和neighbor IPC,来处理分布式硬件和操作系统。
Linux capability
Linux capability是一种对于对 root 权限进行更细粒度的控制,实现按需授权,从而减小系统的安全攻击面的安全机制,用于补充对于root权限粒度控制不足的划分。其实就是一种权限控制
distributed capabilities:XPU-Shim 使用分布式对象和功能为用户空间应用程序维护全局资源和状态。定义了两个分布式对象:CAP_Group是记录进程所有capability的对象,IPC是进程间连接的对象。然后该原语有两个功能:
- XPU-Shim为每个进程维护一个CAP_Group,保证进程具有全局唯一的ID以识别进程。
- 在XPU-Shim中设计一个全局的权限管理方法,具体表现为:
CAP_Group (每个进程) 维护一个功能列表,包括目标分布式对象和权限。一个特殊权限是owner,它可以使用grant_cap授予访问对象到另一个进程的权限。所有者可以使用revoke_cap撤销该能力。在XPUcalls中检查能力 (或权限),例如,进程只有在具有读或写权限时,才能使用xfifo_connect连接到xpu-fifo。
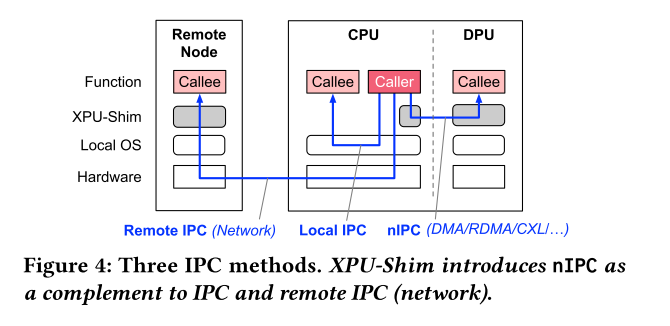
Neighbor IPC:nIPC是允许进程与另一个进程 (在不同的PU上) 通信的基元。nIPC依赖于类似的基于网络的通信方法(比如PCIe),但是作为同一台机器,无服务器运行时可以使用简单的软件堆栈进行通信,并且不需要通过API网关。
目前,xpu-shim支持FIFO风格的通信机制,即xpu-fifo。与现有操作系统类似,我们使用分布式功能 (或文件描述符) 来管理应用程序的fifo。
Miscellaneous XPU Operations
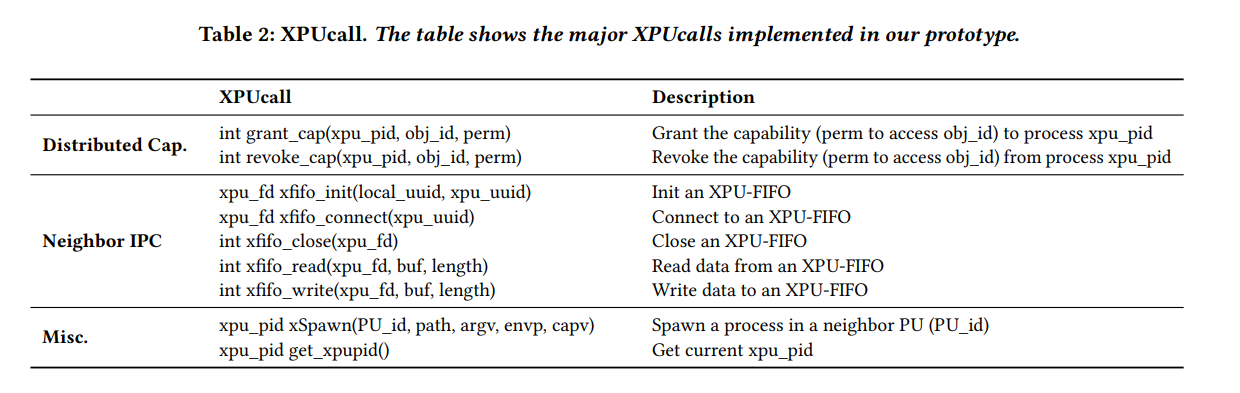
XPU-Shim引入了全局spawn,它遵循Unix系统中的spawn接口,以允许进程在其他PUs上启动新程序。如表2所示,xSpawn需要PU_id字段,该字段指示spawn的目标PU。XPU-shim在父级和子级进程之间不共享任何隐式权限,并且依赖于capv (功能数组) 来允许父级向子级显式授予权限。
Vectorized Sandbox Abstraction
docker runc以及kata等容器实现的都是OCI的接口,如表3的上半部分

利用常规的OCI接口实现FPGA沙箱运行时(称之为runf)有一些限制:
- OCI接口在FPGA等异构设备上的可扩展性较差。与通用的PUs不同,我们只能在具有1个FPGA设备的机器中运行1个FPGA实例
- 明确删除沙盒会产生不必要的成本,在这些情况下是不必要的。在FPGA中,刷新的功能不会占用任何资源,并且在创建新的FPGA无服务器功能时可以轻松替换。
对于矢量化沙箱,做了以下三个扩展:
- 沙盒创建被向量化为**create *vector<sandbox, func-id>***。这意味着runf可以一次创建一组FPGA沙箱。
- 类似于创建,开始界面被向量化为***start vector<sandbox-id>***。该扩展支持并发执行,这有利于通过有限的 FPGA 设备实现自动扩展。
- Molecule 不会明确销毁 FPGA 沙箱,即删除命令将为空并直接返回(但 runf 会更新沙箱状态)。真正的销毁操作发生在下一个创建操作中,它将用新的硬件实现替换当前的硬件实现。这有效地提高了删除性能。该方法不会为下一个创建操作增加开销,因为它不包括擦除操作。
矢量化沙箱依赖于 FPGA 中的包装器来保证实例之间的安全性和性能隔离, XPU-Shim 利用矢量化沙箱抽象来抽象具有出色性能的硬件异构性。
Molecule Design
1、可以管理具有异构设备的工作机器,例如DPU,FPGA,智能I/O设备等。
2、不依赖于主机OS来提供单OS抽象,而是依赖于分布式垫片XPU-shim来管理分布式OS上的功能。
3、应该支持异构计算机上的无服务器机制 (例如,基于fork的启动)。
异构serverless计算
开发人员需要基于 Molecule 支持的特定语言运行时(例如 Python)来编写他们的功能。
如图5a所示,我们为CPU (平台中的x86服务器) 和DPU (平台中的Arm pu) 提供了相同的语言运行时,因为它们支持通用编程。

Molecule要求最终用户将资源显式分配给功能,并根据其价格和硬件能力选择pu的类型 (即CPU或FPGA)
DPU的价格最低,FPGA的价格最高。用户可以选择多个设置,让平台决定如何安排实例。然后,根据用户的配置,API网关将函数的实例调度到具有该函数可以执行的所需PU类型中的至少一种的计算机。
开发人员可以在我们的FPGA运行时 (图5-b) 中编写其FPGA功能,并将功能上传到平台以生成FPGA镜像。
Molecule架构如图6所示:
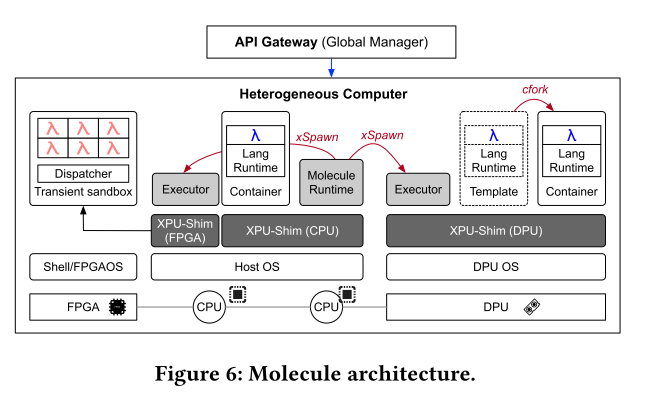
Molecule 服务于来自全局管理器的无服务器请求。它可以在异构计算机中的任何PU (图中的主机CPU) 上运行,并使用xpu-shim管理其他PU中的功能。Molecule将通过xSpawn在其他pu上启动executors,后者负责使用矢量化沙箱抽象管理本地函数实例。执行器从Molecule(通过nIPC) 接收命令,在本地操作系统上执行命令,并返回结果。对于无法启动通用程序的加速器 (例如FPGA),我们在邻居CPU/DPU上启动虚拟xpu-shim实例 (例如图中的xpu-shim For FPGA)。此实例负责运行相应的执行器并管理加速器。
优化启动延迟
函数实例可以通过冷启动或热启动来处理请求,具体取决于是否有可用的缓存沙箱。函数的第一次执行通常从冷启动开始,冷启动需要准备函数映像、创建沙箱、加载函数代码。冷启动通常会导致长延迟,例如,在复杂的Java函数中> 1s; 这是大多数函数的主要成本。
基于Fork的启动和基于快照的启动是两种最广泛采用的用于减少启动延迟的优化。Molecular遵循研究路线,有两个新的贡献:
- 我们提出了cfork,这是第一个实现 <10ms启动延迟的容器级分叉。cfork旨在支持异构计算机。
- 像FPGA这样的加速器不能利用fork来提高启动延迟,因此Molecule利用矢量化沙箱抽象将多个无服务器实例组合成一个映像,这增加了为传入请求击中缓存实例的可能性。
容器分叉 (cfork) 继承了Catalyzer中沙盒分叉的思想,从一个预先准备好的模板容器 (在CPU和DPU上) 生成新的实例,克服了三个挑战:
- 容器可能包含多线程甚至多进程,由于Unix fork仅传播分支线程,因此很难正确有效地克隆它们。cfork提出了forkable language runtime: 一个负责分叉多线程实例的无服务器函数的包装器。语言运行时会暂时将所有线程合并为一个线程,将多线程上下文保存在内存中,并在cfork之后将其扩展为多线程。
- Molecule需要将分叉的函数实例从模板容器迁移到新的容器中进行隔离
- cfork应该支持异构计算机上的多操作系统。
Molecule 将缓存函数实例,而不是fork,以减轻 FPGA 上的冷启动成本。
优化函数DAG通信
无服务器应用程序通常由链功能 (也称为无服务器DAG) 组成,因此通信延迟很重要。无服务器平台通常在所有情况下都使用网络和API网关进行通信,当功能在一台机器上运行时,这可能会产生不必要的成本。
Molecule利用XPU-shim在异构计算机中支持基于IPC的通信,从而允许不同PU上的功能像通过nIPC在单个PU中进行通信。
nIPC-based DAG call. 现有系统通常依靠中间实体 (例如,SAND中的本地总线和Nightcore中的引擎) 来传输消息。Molecule实现了一种 “直接连接” 方法,该方法直接在调用者和被调用者函数实例之间建立连接,即在两个函数之间使用fifo建立全双工连接。
**Supports for DPU. **由于 nIPC 提供了 XPU-FIFO 抽象,这与单 PU 系统中使用的本地 FIFO 几乎相同,因此对 CPU-DPU 异构计算机的支持工作很小,主要区别在于函数应将其 FIFO 注册到 XPU-FIFO 以允许其他 PU 上的进程访问。
Supports for FPGA. Molecule通过利用DRAM数据保留来实现零拷贝方法,这是一种先进的FPGA特性,允许Molecule加载新的FPGA映像,而无需擦除FPGA附加的DRAM中的数据,即数据被持久化。在这种情况下,调用者FPGA功能可以将数据留在FPGA DRAM中,而被调用者FPGA功能可以直接使用数据而无需数据移动。
实现与优化
我们提供了一个XPUShim库 (1,460行C代码),它提供了进程调用的XPUcall接口。Xpu-shim将利用底层互连在pu之间连接和同步状态。在我们的设置中,DPU和CPU通过RDMA (这是唯一导出的基于PCIe的通信方法) 进行通信,而FPGA和CPU通过DMA进行通信。
我们基于矢量化沙箱抽象实现了Molecule。在CPU和DPU中,抽象是基于Docker runc实现的 (通过始终传递一个大小的向量)。在FPGA中,我们实现了一个新的运行时runf,它将管理FPGA无服务器功能。Molecule支持两种最常用的语言运行时,Node.js和Python,占AWS for CPU和DPU的90% 功能,并提供一个基于OpenCL和Xilinx Vitis的FPGA语言运行时。
XPUcall optimizations. 由于xpu-shim是系统中的另一个进程,因此我们需要一种IPC方法来在用户进程和xpu-shim之间进行通信。如图7-a所示的两次IPC往返可导致DPU中的显著高成本。提出了两种优化方法:
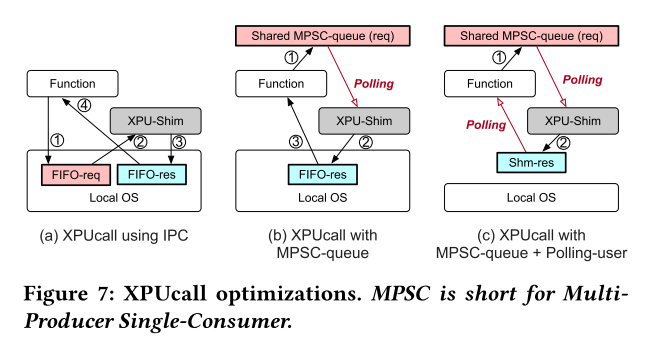
图 7-b 显示了 XPU-Shim 在 MPSC(多生产者单消费者)队列上轮询并依赖 IPC 通知进程 XPUcall 响应的情况。这可以将 IPC 往返次数从两次减少到一次。设备中的优化是合理的,因为 XPU-Shim 可以固定到专用内核以获得更好的性能。
此外,我们可以进一步让进程轮询共享内存以获取响应,从而消除 IPC 成本,如图 7-c 所示。在我们的评估中,我们选择第二种方法作为默认方法。
局限性:我们的原型没有实现DPU和FPGA之间的直接通信。相反,我们依靠主机CPU来转发DPU和FPGA之间的数据,即CPU拦截的通信。
实验
通过评估回答以下问题:
- XPU-Shim如何降低跨PU通信延迟
- Molecule 能否在异构计算机上实现更好的可扩展性和性能?
- Molecule能否实现比商用无服务器系统更好的性能?
- Molecule能否在异构计算机上实现无服务器的低启动延迟?
- Molecule 能否在异构计算机上实现无服务器的低通信延迟?
- Molecule如何减少无服务器应用的端到端延迟?
- Molecule 与最先进的无服务器系统相比如何?
- 支持新的加速器有多容易?
baseline:Molecule-homo(Molecule的同构版本),Molecule不适用XPU-Shim
然后就是各种吹,这里也不多赘述,有兴趣可以去看原文
总结
本文提出了Molecule,这是第一个支持异构计算机的serverless系统。Molecule经过精心设计,可以通过shim layer(xpu-shim) 和vectorized sandbox抽象来抽象出硬件分布和异质性。我们的结果表明,Moleclue在可扩展性和性能方面带来了显著的好处。我们相信Molecule将激励许多未来的异构无服务器计算工作。