The Demikernel Datapath OS Architecture for Microsecond-scale Datacenter Systems

论文链接: https://doi.org/10.1145/3477132.3483569
背景
- IO设备与系统之间的交互时间必须要在亚微秒或者纳秒的单位下,才不会成为瓶颈。
- 现有的kernel-bypass工作在数据路径中消除了内核,但是没有替换内核,但是现有的工作不是一个通用的、可以移植的kernel-bypass库。
本论文提出了demikernel,一个灵活的数据通路操作系统架构。专门为异构kernel-bypass设备设计的。Demikernel有以下三个特点。 - 具备对微秒级应用数据通路的管理功能。
- 统一的API接口(PDPIX)。
Demikernel与传统的控制平面操作系统(Linux,Windows)一起运行,且由一些libos组成,每一个libos是用于特定设备的。可以在特定场景下卸载到kernel-bypass设备上。
Demikernel灵活地适应各种硬件和操作系统卸载的异构kernel-bypass设备。 - 本论文用rust实现了俩原型。
kernel-bypass的需求
支持异构操作系统的卸载
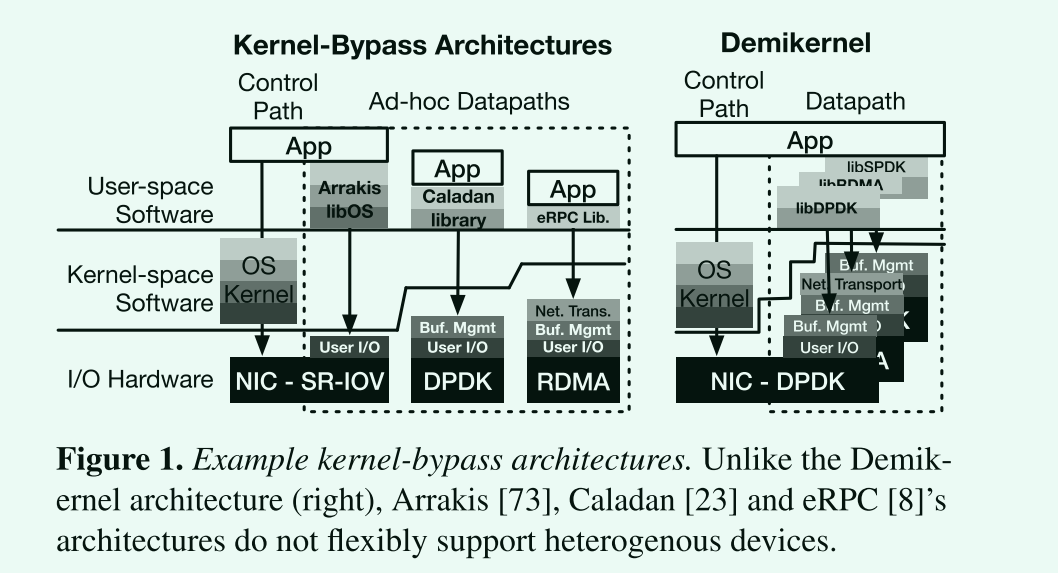
现有的kernel-bypass architecture在特定的设备上会提供不同的特性,因此移植性是一个需求。
例如:DPDK只提供了原始的NIC接口,RMDA实现了具有拥塞控制和可靠传输的网络协议,因此二者往往配合使用。
卸载和设备复杂性是一个trade-off问题。DPDK更加通用广泛,但是RMDA的CPU开销和延迟都很小。0拷贝IO
问题
kernel-bypass需要进行一个地址转换(IOMMU),这需要和CPU的IOMMU和TLB协调。 - kernel-bypass设备需要指定DMA的内存,且固定在操作系统内核中。
- 例如RDMA就是具有DMA功能;DPDK和SPDK使用内存池。导致了一个问题:在原先的kernel-bypass系统中,这些本应由内核管理的机制需要由应用开发者实现。
- 内核与kernel-bypass设备的协调。
- 例如,TCP重发的时候,缓冲区已经释放导致无法重发。
- 微秒级别调度CPU
demikernel的设计目标
- 简化微秒级kernel-bypass设备的系统开发。
- 提供跨异构设备的可移植性。
- 实现纳秒级的延迟开销。
实现方法
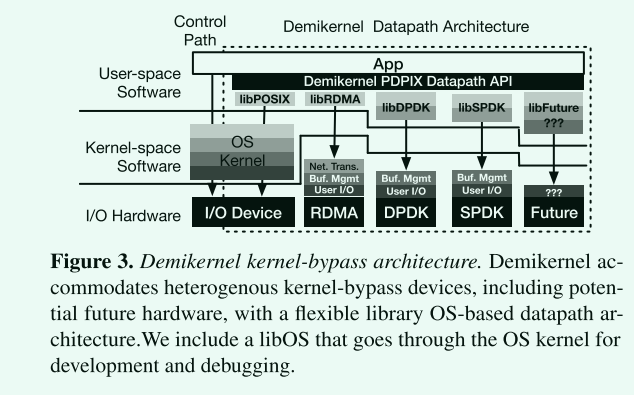
- 将kernel-bypass设备视为数据通路内核,通过可换的libos实现对异构设备的兼容。统一了库的接口,成为PDPIX。
- 为了提供OS的管理特性,Demikernel在各个异构设备原有软件栈的基础上以LibOS的形式对其所需要对OS职能进行增加和补充。
- Demikernel尽可能将OS功能卸载到设备上,且用软件实现。
- demikernel libOS可以用不同的语言实现。
PDPIX API

lib设计
每个操作系统都由可以互换的库操作系统组成,这些库操作系统运行在具有传统内核的不同kernel-bypass设备上。每一个lib除了专门用于特定的设备,还由IO堆栈、内存分配器、协程调度程序组成。
想将lib接入则有三个问题 - 如何解决kernel-bypass设备对内存的使用。
- 统一内存接口。
- 减少调度的开销(满足微秒级应用的要求).
内存管理
- 每一个libos都有一个内存分配器。该内存分配器是一个基于内存池的分配器。通过超级块的方式管理DMA内存和引用计数。
- 对于每一个IO,可以通过get_rkey接口获取rkey。同时讲rkey保存在超级块头部。
- 通过引用计数,实现了UAF保护。
协程调度
demikernel有三种协程。 - 用于IO堆栈的快速路径协程,用于轮询。
- 用于其他IO栈工作的后台协程(TCP窗口)。
- 每个阻塞qtoken的应用协程。
调度器调度的优先级是 应用协程-后台协程-快速路径协程。然后进行FIFO调度。
为了实现纳秒级别的调度,调度器维护一个唤醒快列表,集中维护64个不同协程的就绪位。通过一个算法去找到可运行的协程。IO处理
每个libos都有一个IO堆栈,用快速路径协程去轮询单个硬件接口以便减少延迟。
设计了一套异步的IO队列。使用异步的方式替换了原先的阻塞IO。
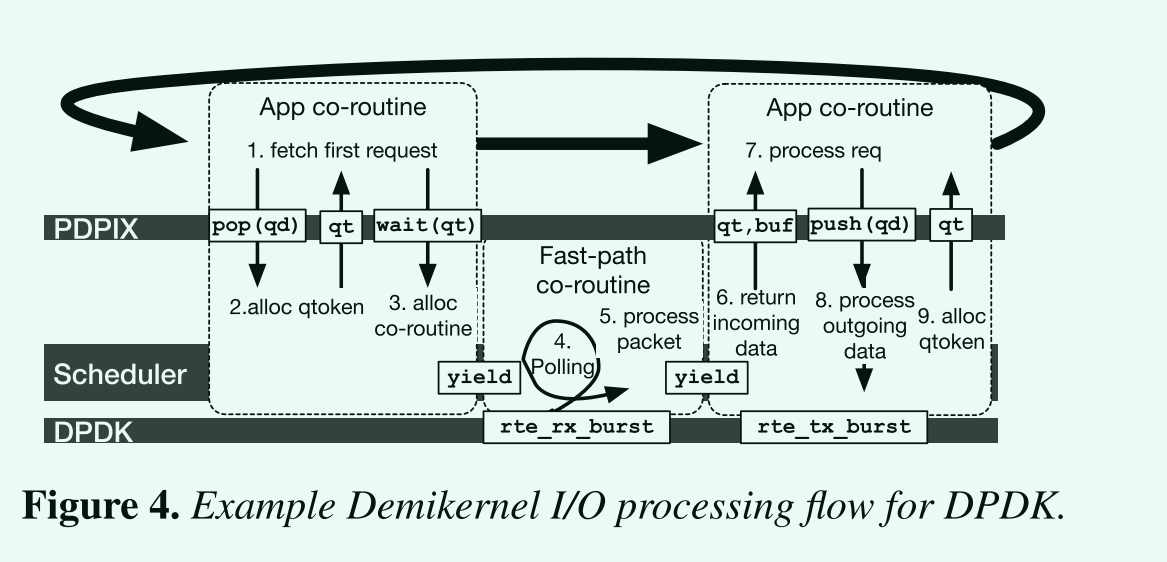
拿DPDK为例,但是也适用于其他IO堆栈。 - 应用调用pop去获取一个数据。
- libos返回一个qtoken给应用,应用可以去wait对应的qtoken。
- libos会为每个等待中的qtoken分配一个阻塞的协程,然后让出CPU给调度器。
- 如果调度器没有其他工作,就调用快速路径协程。
- 快速路径协程是会轮询DPDK的rte_rx_burst。
- 如果发现了一个分组,立刻处理
评估
- 灰色的是在Demikernel中花费的时间
- 黑色是网络和其他延时
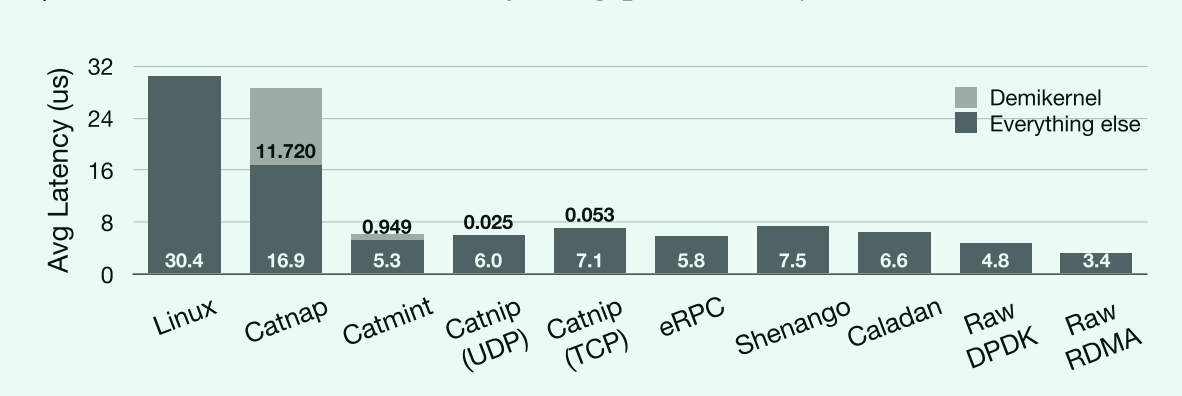
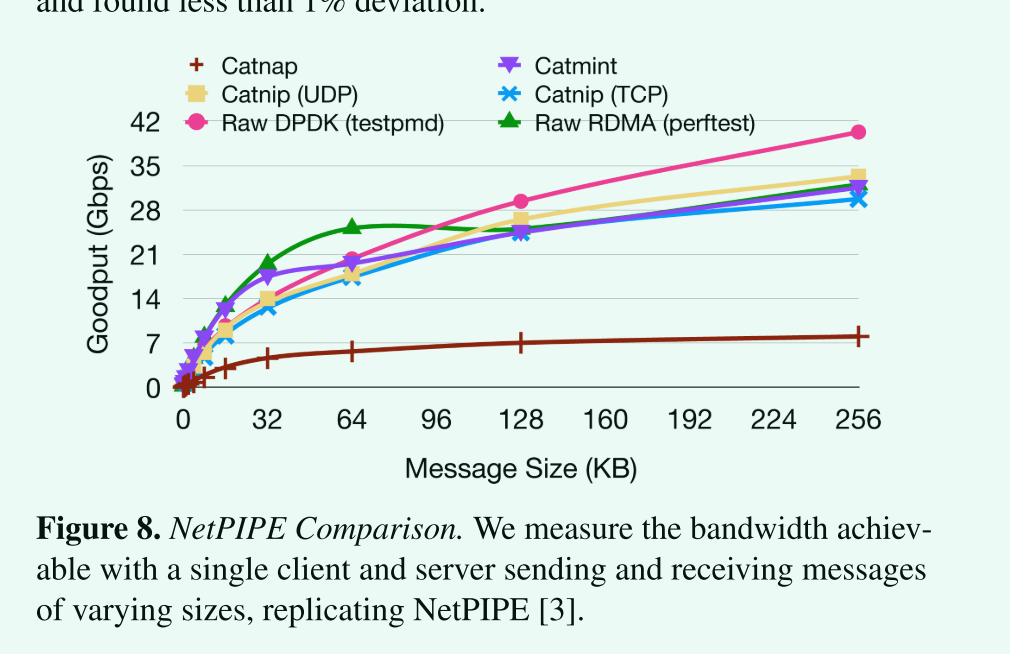
评价
优点 - 用一点点性能开销获得了一个通用性的框架
- 适用于微秒级系统
缺点 - 用了一些rust的语言特性,如果用其他语言做 不知道能不能达到论文中的效果。
- 应用程序的API要调整。