
论文链接:https://dl.acm.org/doi/abs/10.1145/3544216.3544259
开源代码:https://github.com/ucr-serverless/spright
关于eBPF的一些背景:https://www.cnblogs.com/dengchj/p/14919393.html
摘要
Serverless计算承诺在云环境中提供高效、低成本的计算能力。但是,以开源平台 (例如Knative) 为代表的现有解决方案包括重量级组件,这些组件破坏了无服务器计算的这一目标。此外,这种无服务器平台缺乏数据平面优化,无法实现高效,高性能的功能链,从而促进流行的微服务开发范例。他们使用复杂和重复的功能来构建功能链,严重降低了性能。“冷启动” 延迟是另一种挑战。
SPRIGHT,这是一个轻量级,高性能,响应迅速的无服务器框架。SPRIGHT利用共享内存处理,通过避免不必要的协议处理和序列化反序列化开销,极大地提高了数据平面的可伸缩性。SPRIGHT通过扩展的Berkeley数据包过滤器 (eBPF) 广泛利用事件驱动的处理。我们创造性地使用eBPF的套接字消息机制来支持共享内存处理,开销严格按负载比例。相较于DPDK大幅降低了CPU在数据面上的开销。
实验结果表明相较于Knative,SPRIGHT在吞吐量上实现了数量级的提高并降低了CPU开销,降低冷启动代价。
引文
Knative平台在编排Serverless应用时存在以下问题:
- 使用重量级无服务器组件。每个Pod都有Sidecar代理,它负责度量收集以用于Serverless编排。但是sidecar必须一直运行,带来的开销较大。具体的为数据副本传输、上下文切换、中断开销。此外,大多数Serverless框架关注HTTP/REST API,需要针对专门的用例进行额外的协议适配,目前的策略是将协议适配作为单独组件,但这种重量级组件设计的开销不可忽略。作者提出一种设想,即不使用这个组件,而完全基于事件驱动调用代码来解决这个问题。
- 函数链接数据平面性差。架构解耦导致组件间通信需要上下文切换,序列化,反序列化,数据复制的开销。当前的设计还在很大程度上依赖于内核协议栈来处理网络数据包到功能pod之间的路由和转发,所有这些都会影响性能。
SPRIGHT,这是一种高性能,事件驱动且响应迅速的无服务器云框架,该框架利用共享内存处理来实现无服务器功能链中的高性能通信。它的贡献如下:
- SPRIGHT网关,这是一个链范围的组件,以促进无服务器功能链中的共享内存处理。SPRIGHT网关合并linux内核中的协议栈处理,并将有效负载分发到链中。
- 通过使用基于事件的共享内存通信在无服务器功能链中实现零复制消息传递。
- 使用eBPF (扩展伯克利数据包过滤器) 设计事件驱动的代理 (即EPROXY和SPROXY),该代理有效地替代了重量级的sidecar代理。我们支持度量集合等功能,CPU消耗低得多。
- 通过将对私有共享内存的访问限制为仅该链的受信任功能,我们在SPRIGHT的共享内存处理中在功能链级别实现了分离。SPROXY通过对功能间通信应用消息过滤来进一步限制未经授权的访问。
- 利用eBPF提供的数据包重定向功能来提高无服务器功能链之外的数据包转发性能。与内核网络堆栈相比,基于ebpf的数据平面大大降低了延迟和CPU消耗。
- 我们通过将其作为附加到SPRIGHT网关的事件驱动组件运行来优化协议适配,以避免不必要的网络协议栈处理开销。这种优化可以显著减少延迟。
总的来说就是自定义网关和协议栈,通过内存共享传递Serverless上下文,降低传递、监听的开销。
背景与挑战
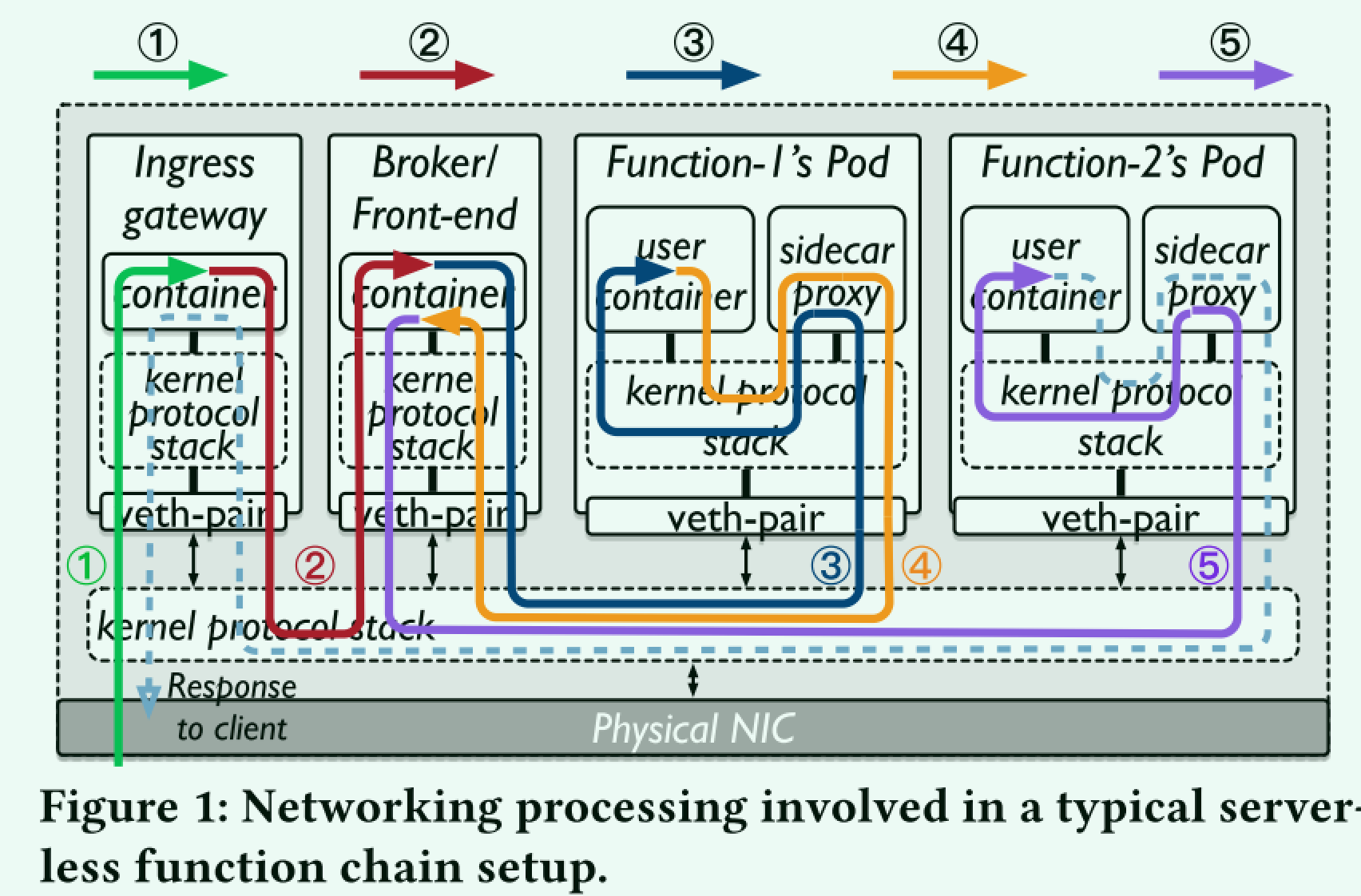
函数链的数据管道使用消息路由,如下所示:
① 客户端通过集群的入口网关向消息代理/前端代理发送消息 (请求)。
② 消息在消息代理/前端代理中排队并注册为事件。
③ 消息代理/前端代理将消息发送到头部的活动pod (第一) 链中的功能,由用户定义。
④ 调用函数pod来处理传入的请求。第一个函数处理请求后,返回响应并在消息代理/前端代理中排队,注册为链中下一个函数的新事件。
⑤ 消息代理/前端代理将此新事件发送到链中下一个函数的活动pod。
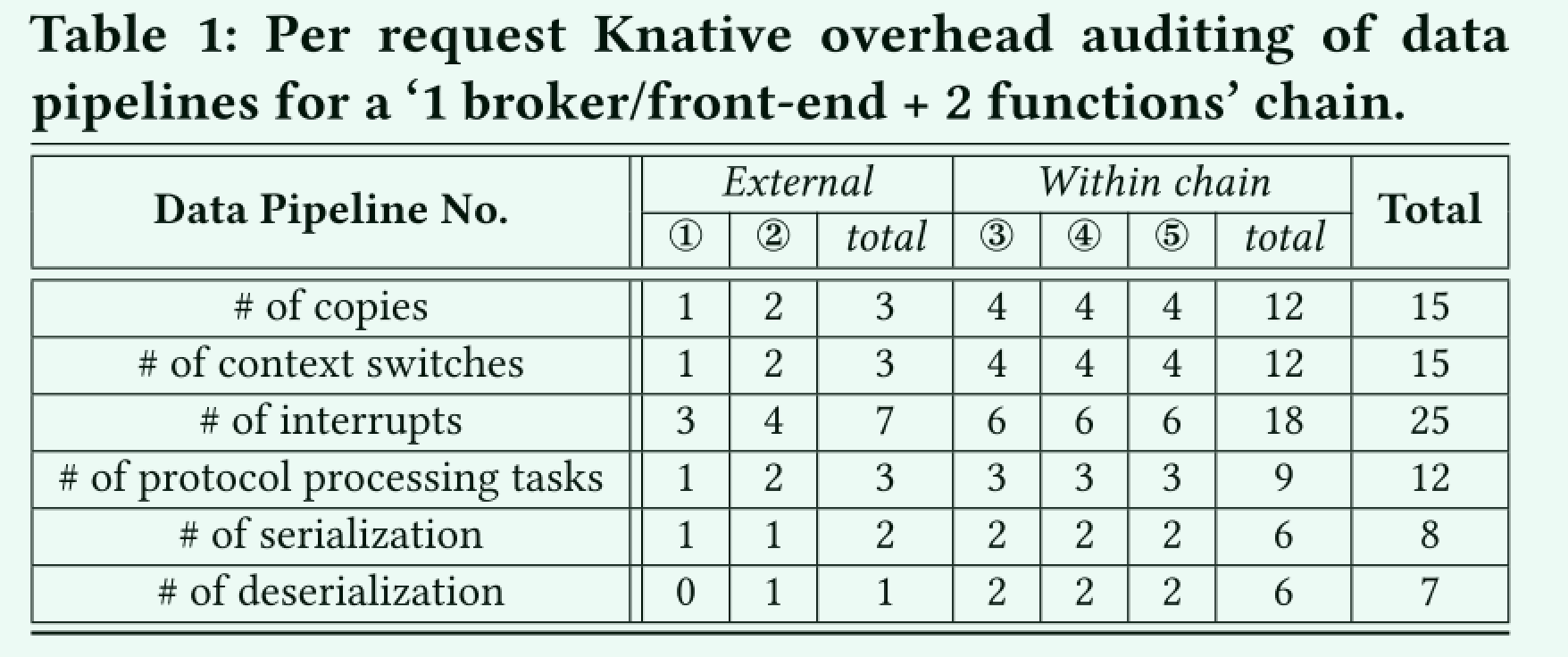
作者总结了这个传输链路中的数据复制、上下文切换、中断、协议处理数据量以及序列化和反序列化的次数,总结出如下的表
作者认为,函数上下文传递过程中proxy -> sidecar -> func-container-1 -> sidecar -> proxy的流程太过于冗余,导致函数上下文传递经历了不必要的开销,它认为理想的情况应该是proxy -> func-container-1 -> func-container-2,即函数间传递不需要绕这么大的弯。
原论文中是总结了四点:
- 过多的数据拷贝、上下文切换和中断。
- 过度、重复的协议处理。
- 不必要的序列化/反序列化。
- 不断运行的重量级组件。
SRIGHT系统设计
总体而言SPRIGHT的设计包含以下要点
- SPRIGHT控制器与控制平面一起工作,与kubelet一起工作。这部分要控制同一个函数组合在同一节点执行。
- SPRIGHT网关充当功能链的反向代理,以巩固协议处理。SPRIGHT网关依赖于内核协议栈进行协议处理,并提取应用程序数据 (即第7层有效载荷)。它拦截对功能链的传入请求,并将有效负载复制到共享内存区域中。这样可以在链内进行零副本处理,避免了不必要的序列化/反序列化和协议栈处理。
- Direct Function Route (DRF):利用共享内存和eBPF的可配置型,允许函数在共享内存间传递数据
- Event Driven Proxy(EPROXY + SPROXY):使用eBPF构造服务网格。
- 安全:限制不同链之间未经授权的访问
- SPRIGHT直接在共享内存上处理负载,精简了适配器间的处理流程。
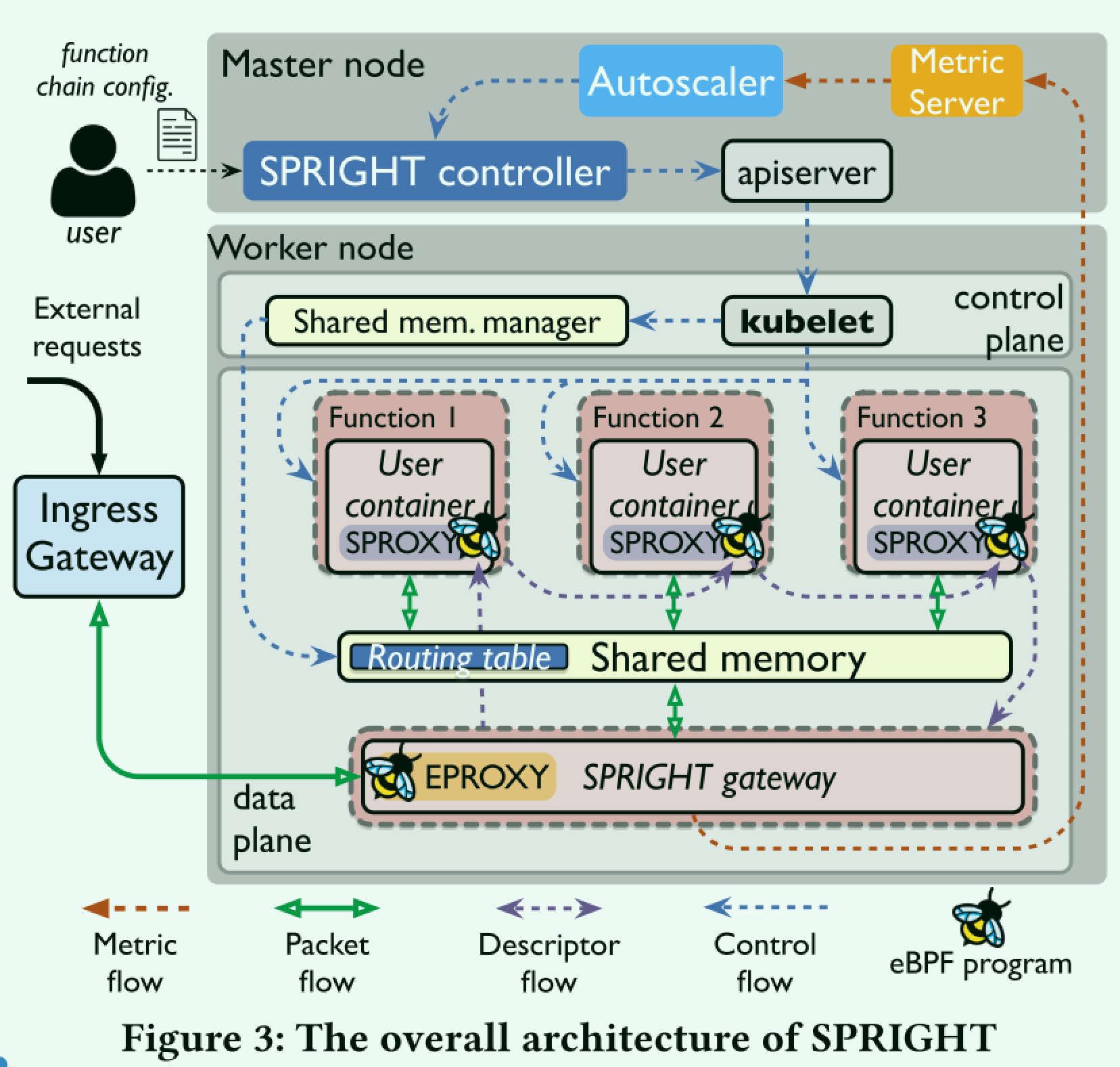
这里的核心点在于函数间通过eBPF和共享内存绕过Sidecar产生的开销,作者在下图中展示了函数间共享数据的流程。
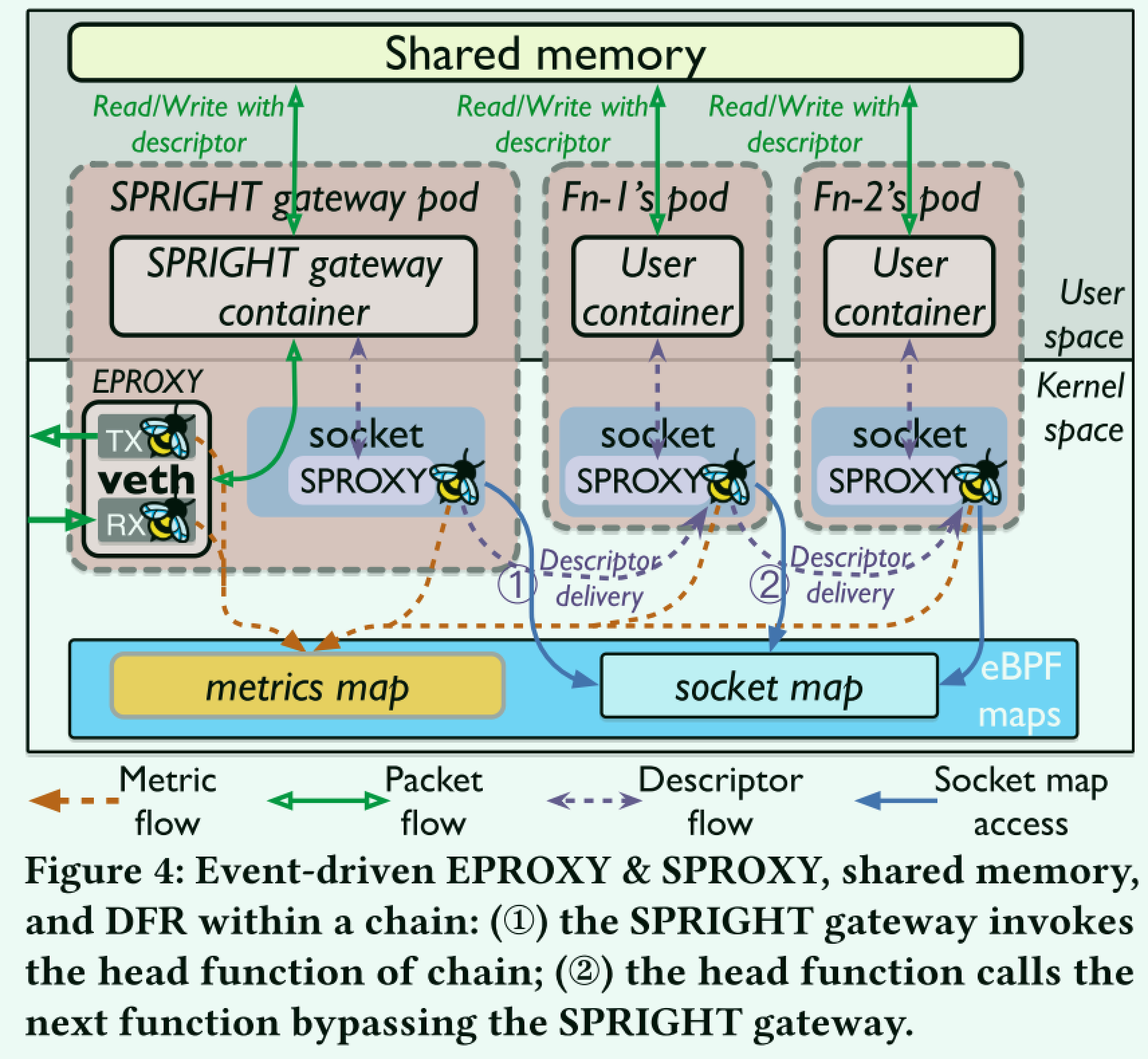
网关在收发到数据包时,唤醒第一个Serverless函数,再通过eBPF数据包的形式绕过网关直接向下一个函数传递数据。需要关注的是,这里待处理的数据都是放在共享内存中,而通过eBPF map传递的是一个描述符,它找到下一个需要传递信息的socket以及函数调用链中数据在共享内存中的信息,由于传递的信息只有描述符,且绕过了复杂的网关,因此传输开销降低。
作者进一步分析了适合共享内存的事件处理机制。对比的是两种方案,一种是基于事件的共享内存处理(可以理解为传递某个中断或者信号来告知进行数据处理,S-SPRIGHT)和基于DPDK的轮询处理(D-SPRIGHT)。
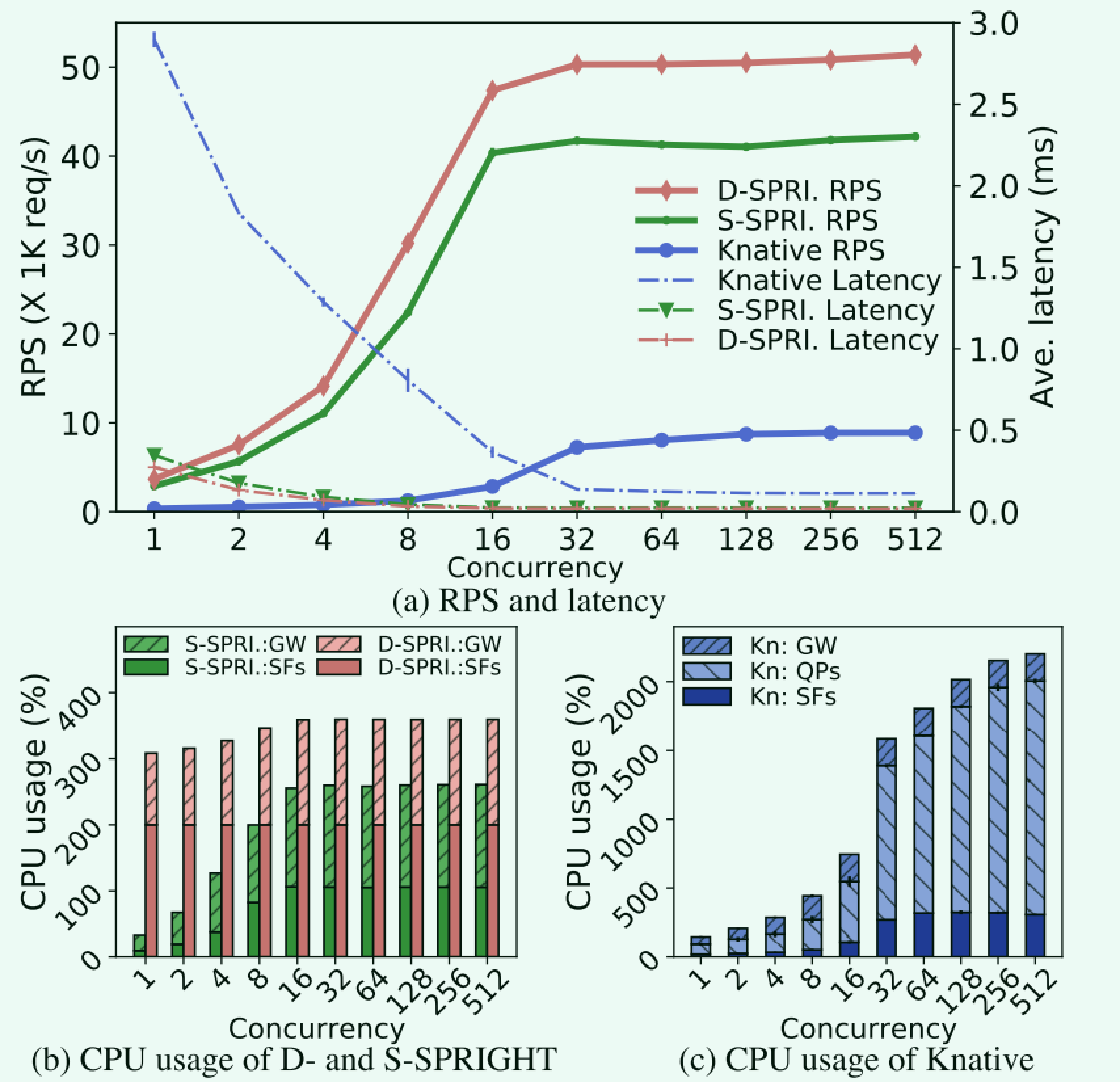
得出的结论是这两种基于共享内存的处理机制在CPU开销和性能上远优于Knative本身的复杂链路。S-SPRIGHT吞吐量略逊于D-SPRIGHT,但是CPU开销在负载规模小的情况下远远优于DPDK。作者在摘要中提到的降低冷启动的代价,说的是监听的代价,降低CPU开销。
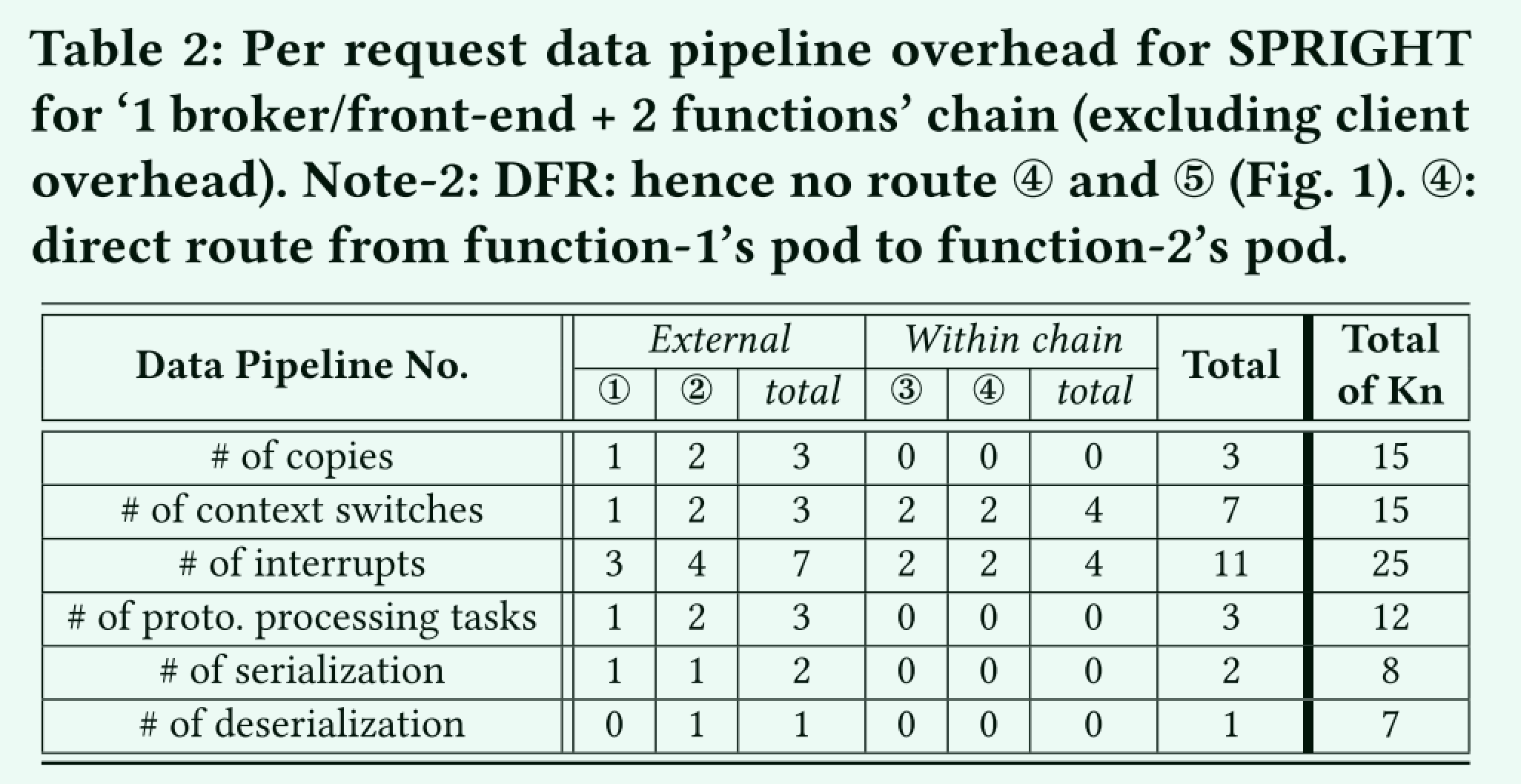
通过上述方式得到了新的调用链开销。可以看到函数外部的调用链不变,但是内部的开销已经被大幅降低。
论文后面还讨论了不同的函数调用链的内存隔离以及跨节点函数调用的实现细节,这里略过。
实验与评估
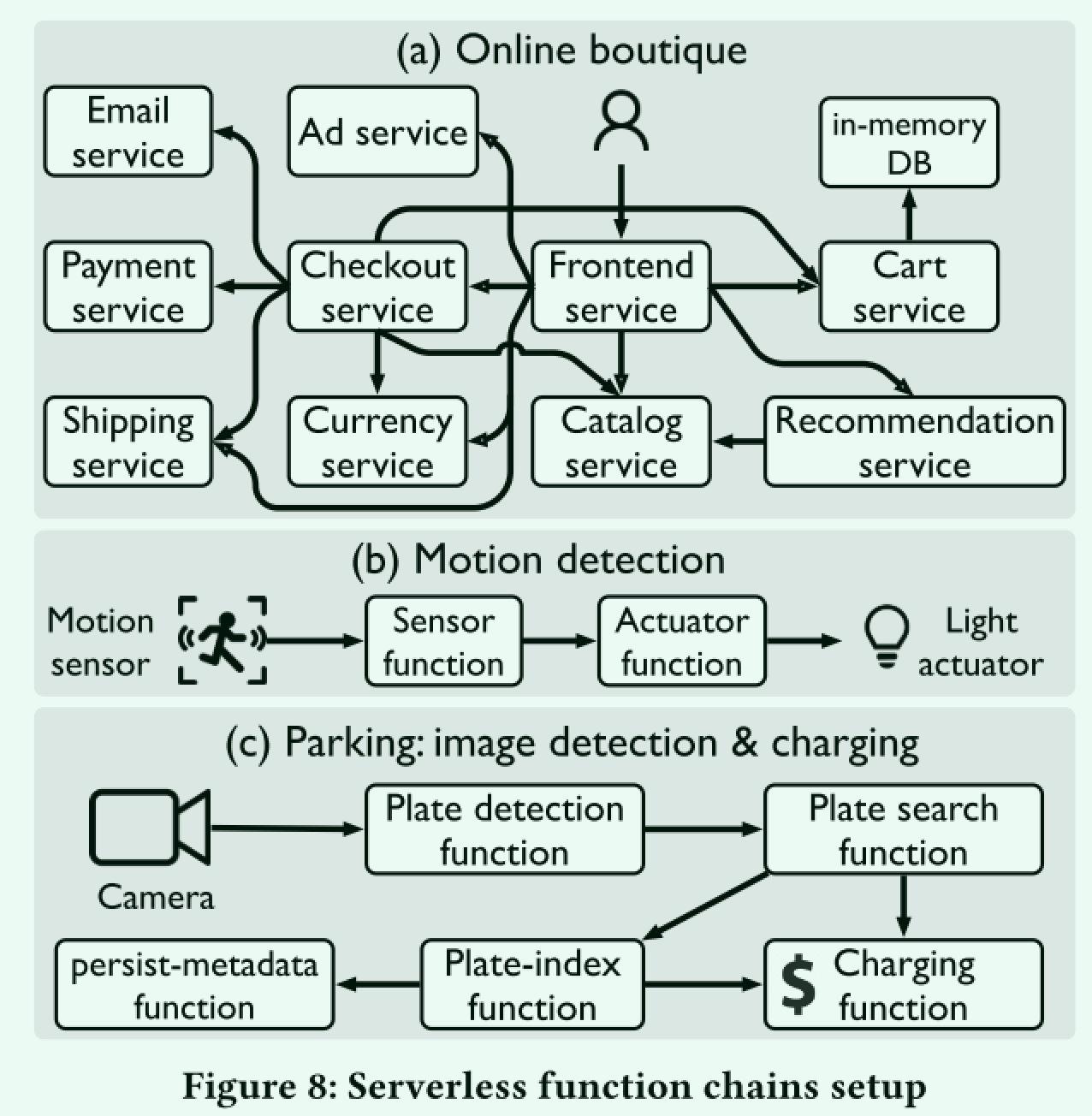
为了研究SPRIGHT及其组件的改进,作者考虑了几种典型的无服务器场景,包括
- 流行的在线购物精品店
- 运动检测器的IoT环境
- 图像检测的更复杂处理和自动停车库的收费
可以看到都是调用链相对比较复杂的场景
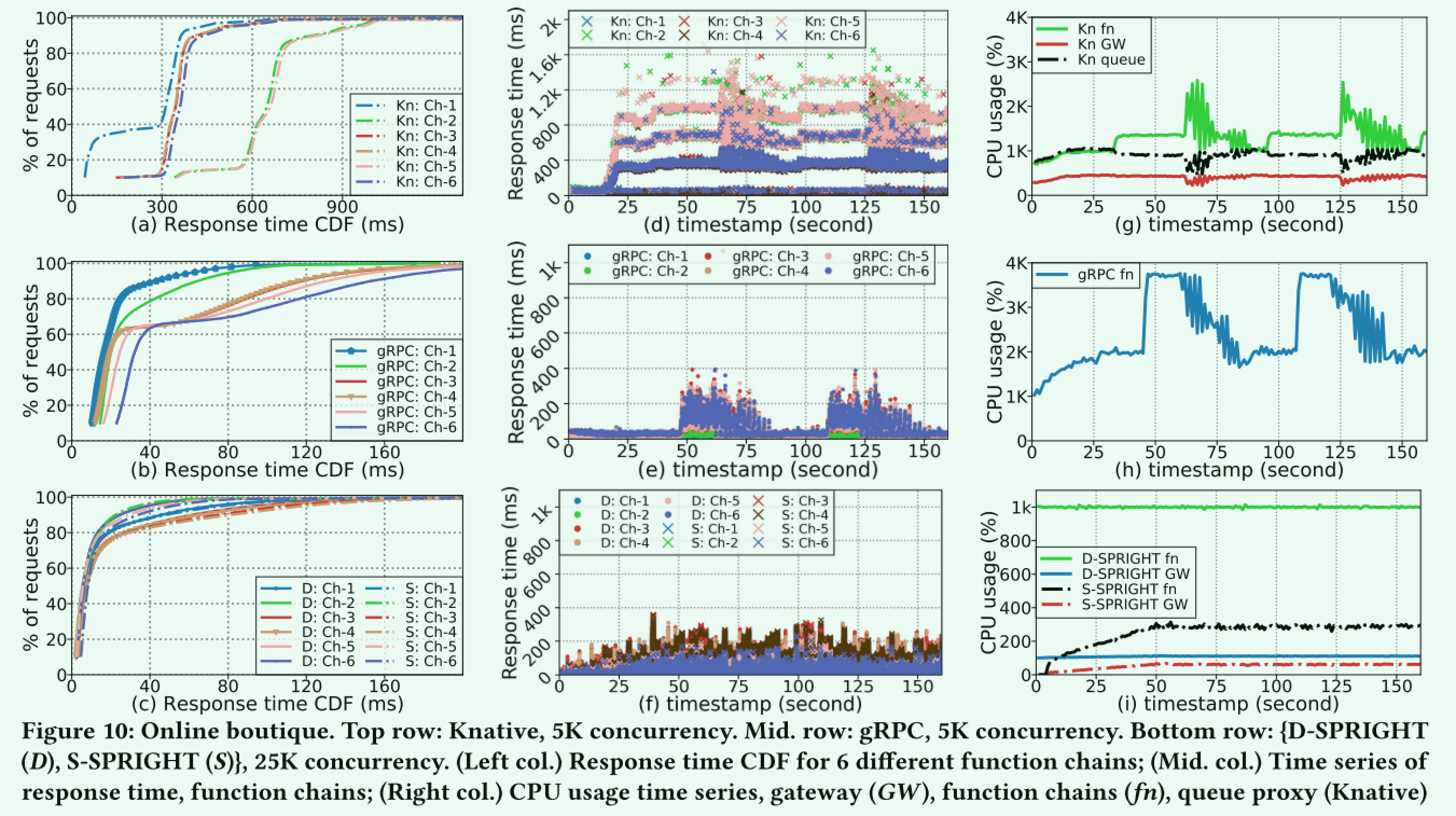
作者这里使用在线购物商城(最复杂的调用链)来做实验。其中顶行: Knative,5k并发。中间行: gRPC,5k并发。底部行: {D-SPRIGHT (D),S-SPRIGHT (S)},25k并发。(左上校。)6种不同功能链的响应时间CDF; (Mid. col.)响应时间序列,功能链; (右列)CPU使用时间序列,网关 (GW),功能链 (fn),队列代理 (Knative)
可以看到,最终S-SPRIGHT在时延分布,不同环节的CPU开销上都相较于gRPC以及Knative原生方案有较大的优势。
相关工作
这篇文章的灵感来源可以从相关工作中获取。
- Understanding Host Network Stack Overheads. SIGCOMM21,探讨了当前Linux系统松耦合设计导致的对高带宽场景下网络的影响
- Parallelizing Packet Processing in Container Overlay Networks. EuroSys21 探讨容器网络堆栈的开销
- Zerializer: Towards Zero-Copy Serialization. HotOS21 主张通过专用硬件将序列化逻辑卸载到DMA路径,初步证明其可行性和预期效益,规避序列化开销。