TJS’22 Toward low CPU usage and efficient DPDK communication in a cluster
论文链接:https://dl.acm.org/doi/abs/10.1007/s11227-021-03942-x
摘要
存在的问题
DPDK 通过轮询的方式来避免中断产生的性能损耗,但由于轮询需要一直执行循环对网卡设备进行监听,不仅会浪费大量的 CPU 周期,还会影响到其他正在运行的应用程序。
目前的解决方案及其缺点
动态电压、频率缩放和低功耗空闲技术。存在的问题是降低频率会很大程度的影响到其他正在执行的任务。
可能的解决方案
通过线程睡眠操作来让出 CPU
背景
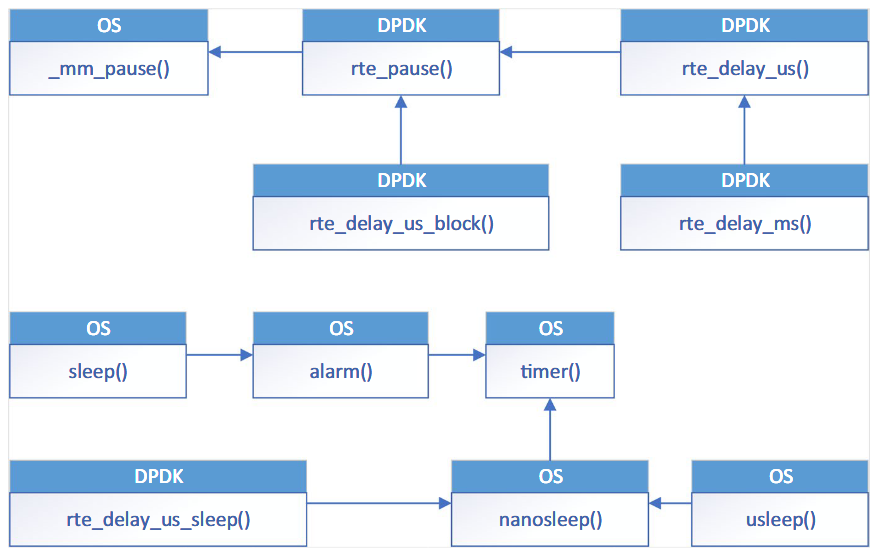
上半部分流程在调用时不会让出 CPU,它以 spin_wait 的方式实现延迟。下半部分会让出 CPU,调用的是 OS 提供的 nanosleep 函数。
使用 DPDK 提供的延迟函数与使用 OS 提供的睡眠函数进行 CPU 使用率的对比
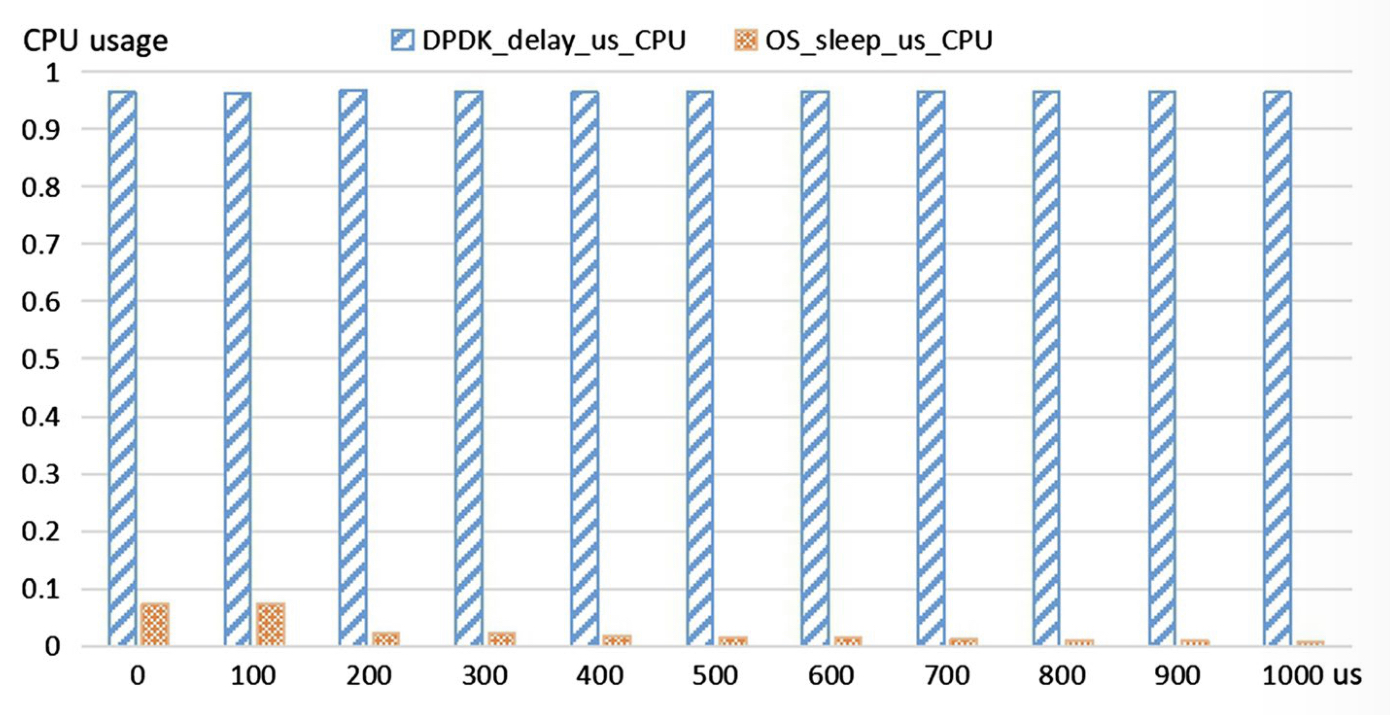
可以看出在使用 OS 提供的 API 时可以显著降低 CPU 的使用率。
此处的延迟针对 receiver
当使用 DPDK 提供的延迟函数时,得出下图
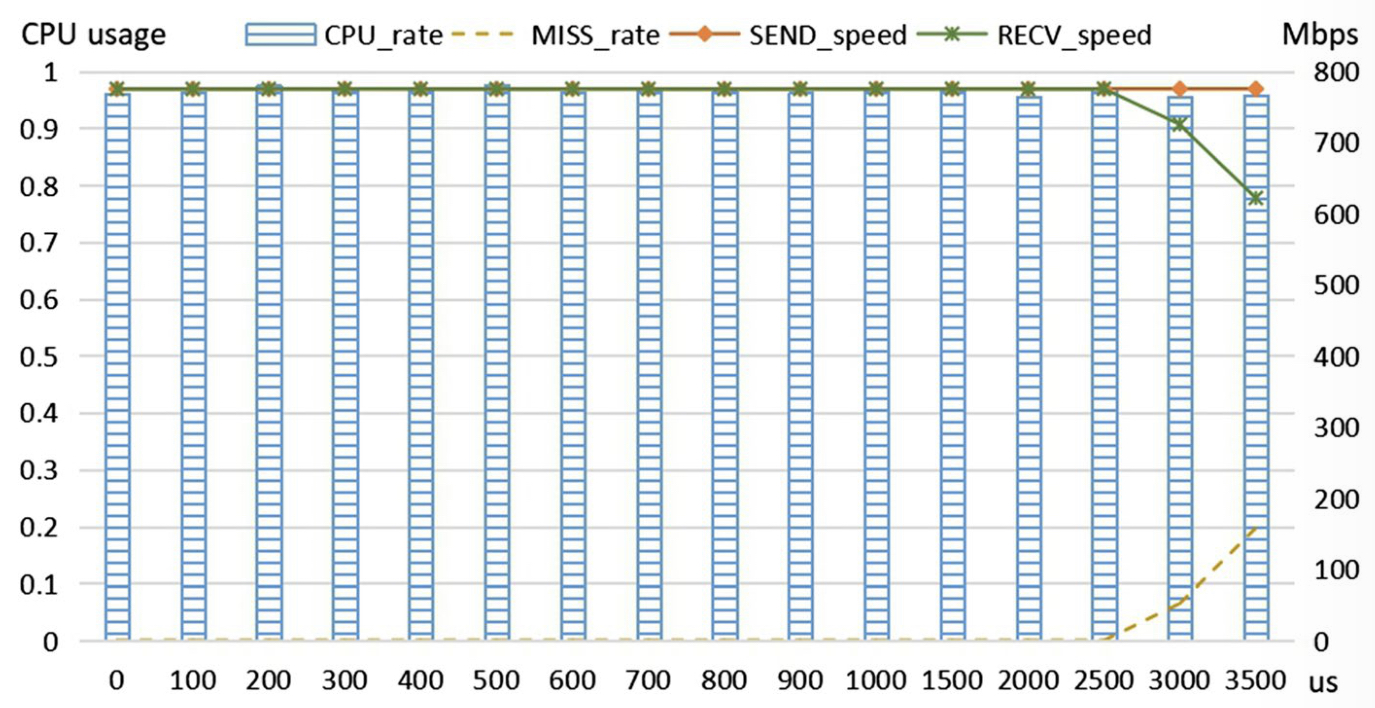
当 延迟时间增加时,CPU 的使用率并没有降低
而使用 OS 提供的 sleep 函数时,得出下图
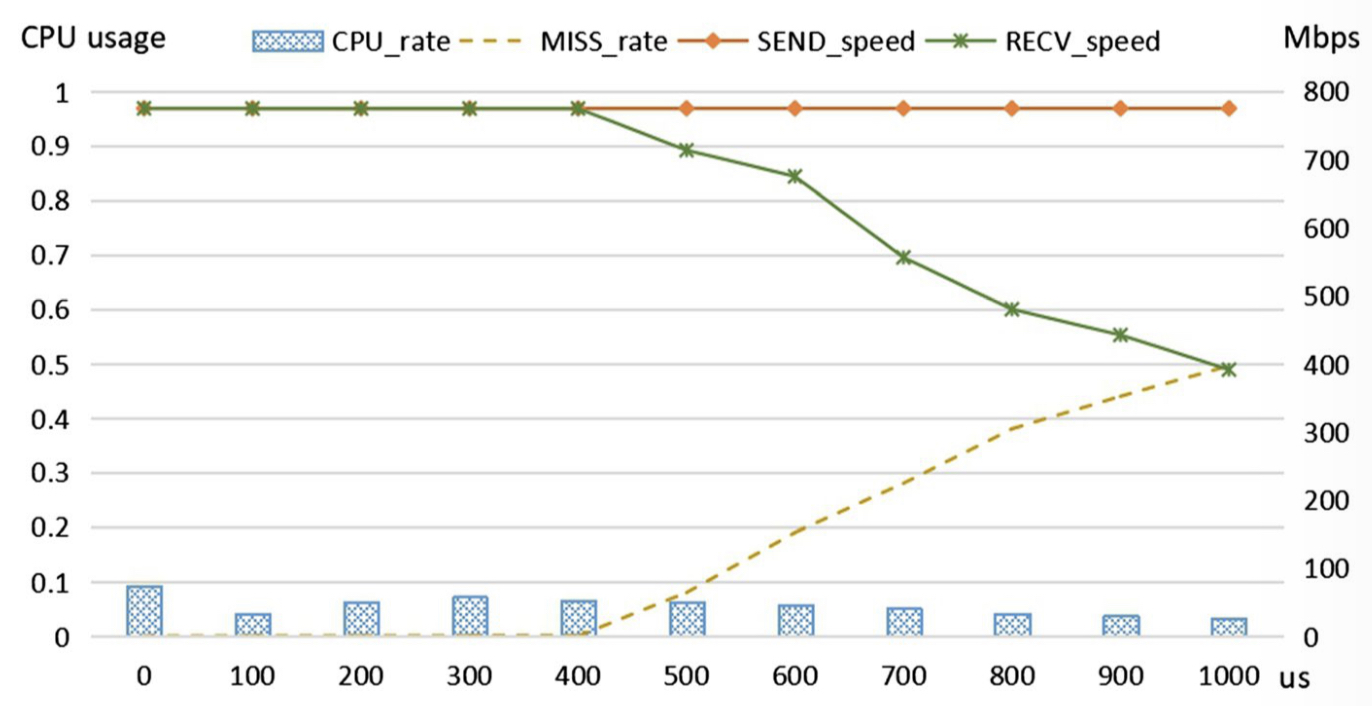
在一定的延迟时间范围内,两者的传输的速率并没有出现明显的差异,但 CPU 占用率有显著的下降。
测试框架
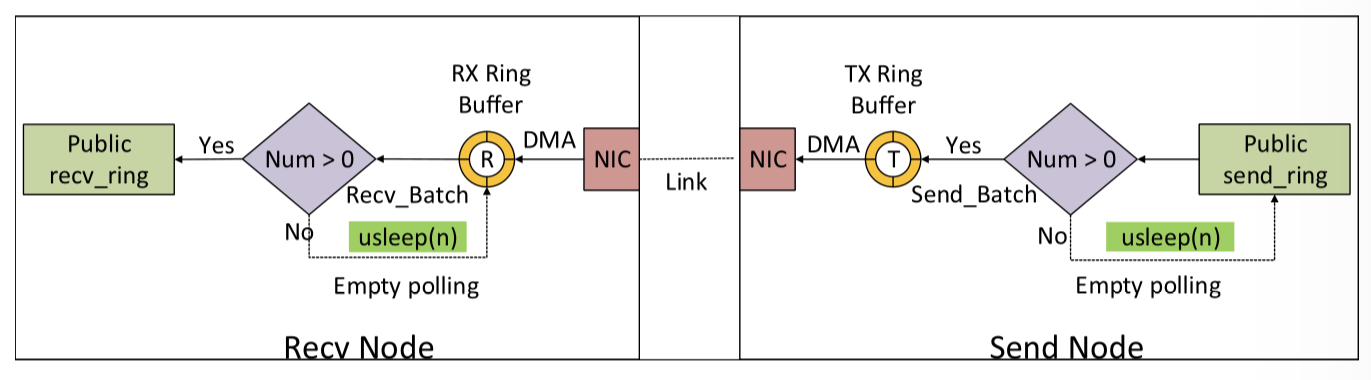
测试数据
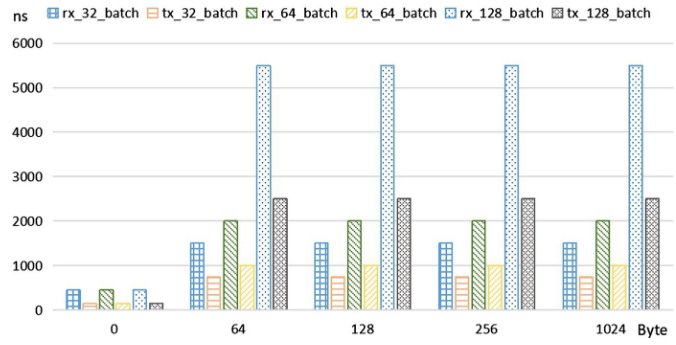
上图为不同批处理大小与数据包大小下流程的执行延迟,当数据包大小相同时,时间消耗会随着批处理大小的增加而增加。
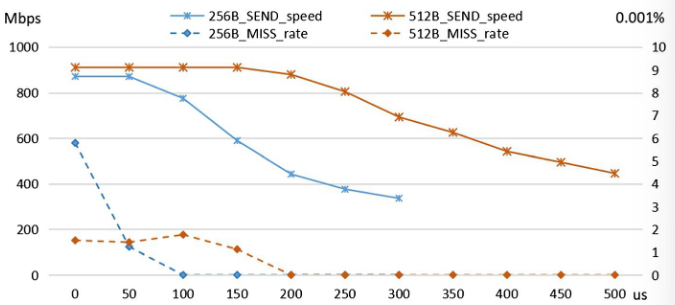
上图为不同睡眠时长和发送方不同数据包大小的传输速度与丢包率(接收方不休眠)随着发送方休眠时长的增加,传输速率和丢包率都会降低
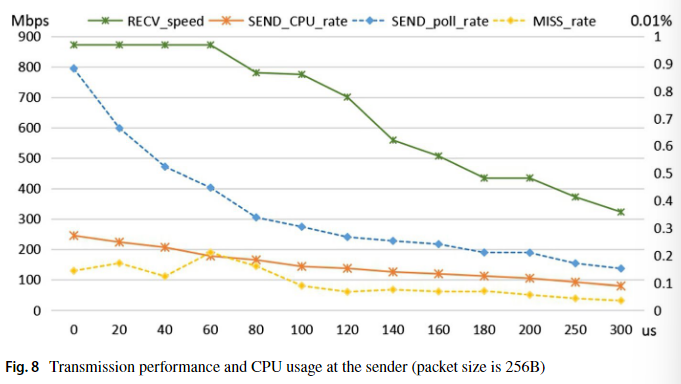
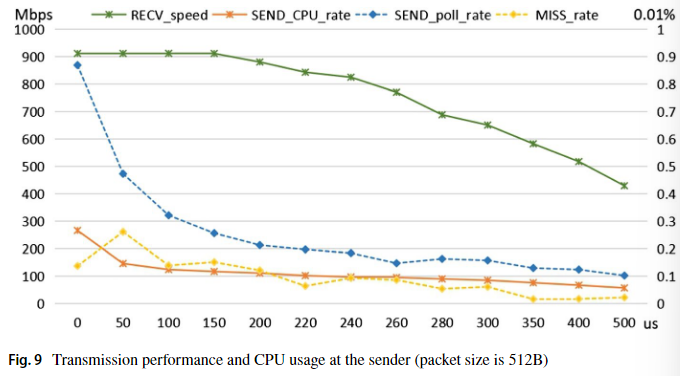
上图为发送端睡眠时长对 CPU 占用率的影响(发送速率和接收速率基本相同)
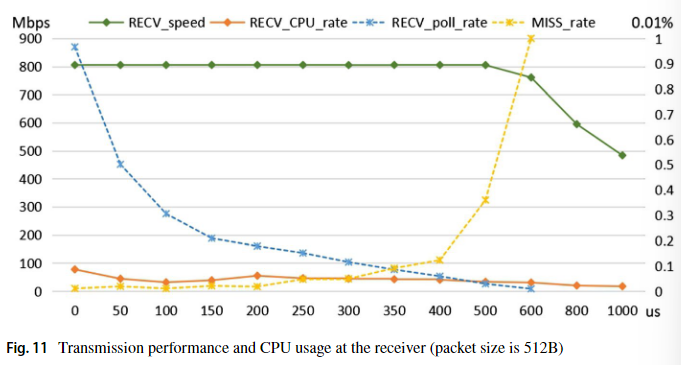
上图为接收端睡眠时长对 CPU 占用率的影响
提出解决方案
使用卡尔曼滤波器预测实时的数据包大小以及数据包传输速率,通过以上两个量结合测试数据对最佳睡眠时长进行动态搜索。
卡尔曼滤波的一个典型实例是从一组有限的,包含噪声的,对物体位置的观察序列(可能有偏差)预测出物体的位置的坐标及速度。
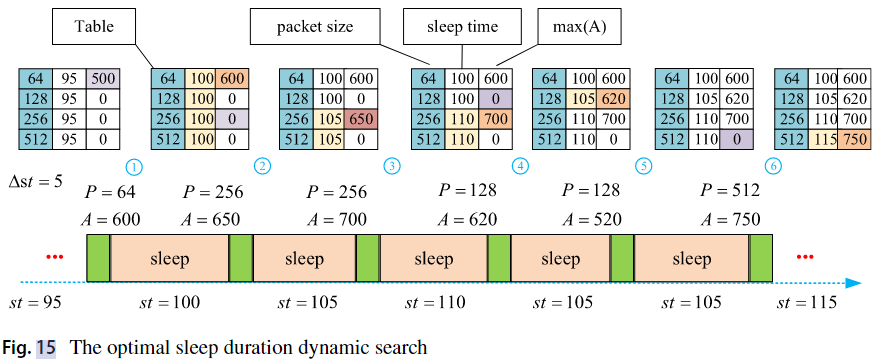
第一列为包大小,第二列为最大休眠时长,第三列为传输速度。P 表示在时间 t 估计的数据包大小,A 表示在时间 t 估计的速度大小。st 表示睡眠时间。
首先根据估计值 P 得到记录表中对应的 max(A) 的值,α 代表对传输速度下降的容忍度。
- 若估计的 A 大于 max(A) * α,则令 st = st + Δst,并对下方的所有行进行更新的操作:如果 st 大于 表中的 sleep time,则将 st 赋值给 sleep time。最后将 A 赋值给 max(A)。
- 若估计的 A 小于 max(A) * α,则直接将 st 设置为表中的 sleep time。