论文发表在ASPLOS’22上
作者团队来自曼彻斯特大学,还是做Unikraft的那帮人
项目链接:https://project-flexos.github.io/
论文链接:https://dl.acm.org/doi/10.1145/3503222.3507759
代码链接:https://github.com/project-flexos/asplos22-ae
视频链接:https://www.youtube.com/watch?v=fKkV4yp97Wc
Abstract
在设计时,现代操作系统被锁定在特定的安全和隔离策略中,该策略混合了一个或多个硬件/软件保护机制 (例如用户/内核分离); 在部署后重新审视这些选择需要大量的重构工作。当推出新的硬件隔离机制时,或者当现有的硬件隔离机制中断时,考虑到各种各样的现代应用程序的安全/性能要求,这种严格的方法显示了其局限性。
FlexOS,这是一种新颖的操作系统,允许用户在编译/部署时间而不是设计时间轻松地专门化操作系统的安全和隔离策略。这种模块化的LibOS是由不同粒度的组件组成。这些组件可以通过一系列硬件保护机制与各种数据共享策略和额外的软件强化进行隔离。操作系统采用探索技术,可帮助用户导航其解锁的广阔安全/性能设计空间。我们实现了该系统的原型,并针对多个应用程序 (Redis/Nginx/SQLite) 演示了flexos的广阔配置空间以及探索技术的效率: 我们评估了80个Redis的FlexOS配置,并展示了在给定的性能预算下,如何将该空间概率地子集为5个最安全的空间。我们还表明,在等效配置下,FlexOS的性能与使用固定安全配置的现有解决方案相似或更好。
从摘要看出,这篇文章需要在大量的配置空间中寻找最安全的libs配置
1. Introduction
论文贡献如下:
- 使用FlexOS,用户可以在构建时决定应将哪些细粒度的OS组件放置在哪个隔室 (例如调度程序,tcp/ip堆栈等) 中,如何为每个隔室实例化隔离和保护原语,使用哪些数据共享策略进行隔室之间的通信,以及应该在哪些隔室上应用什么软件强化机制。为此,FlexOS抽象了在通用API后面划分任意软件时所需的通用操作,该通用API用于将现有的libo改造为FlexOS。(即库的整合)
- 由于这种库的编排存在大量的组合空间,FlexOS还提出一种partial safety ordering技术,在给定性能要求下实现最优资源配置。
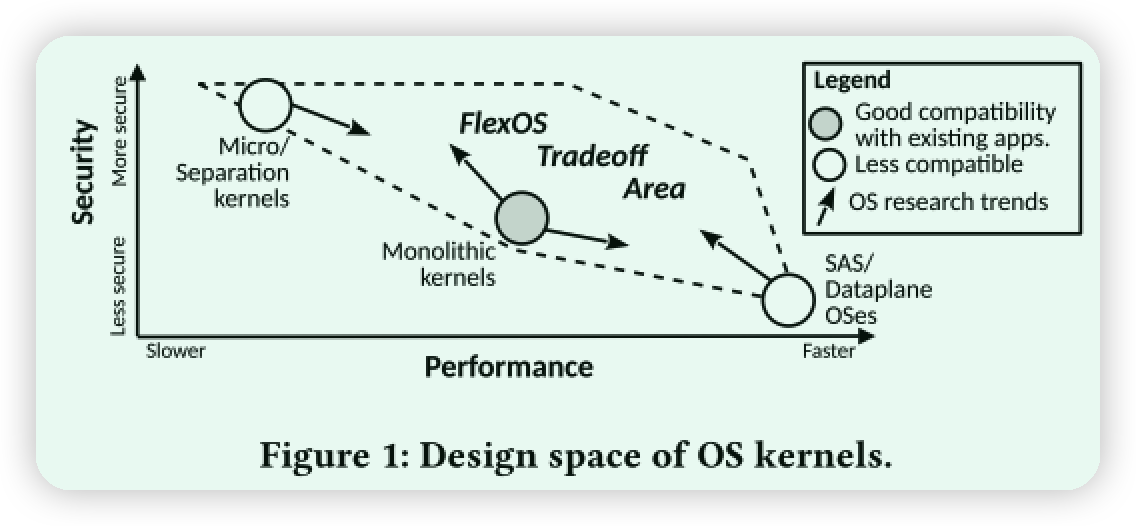
作者希望在微内核空间的绝对安全(但性能低)和完全信任应用的单地址空间操作系统(安全性差)中找到平衡。
实验层面:
- FlexOS支持 Intel MPK和 VM/EPT级别的隔离,以及广泛的加固机制(CFI(Control-Flow Integrity),ASAN(address sanitization,地址净化技术,用以避免一些潜在的地址泄漏问题))
- 使用四个流行应用程序进行的评估展示了FlexOS解锁的广泛安全性与性能权衡空间: 我们评估了Redis和Nginx的160多个配置。
- 证明了在等效配置下,FlexOS的性能更好或类似于基线/竞争对手: 整体内核,SASOS(Single-Address-Space OS),微内核和分隔的libos。
2. Flexible Isolation: Principles and Challenges
2.1 Principles
(P1) Flexos组件的隔离粒度应该是可配置的。分隔策略,即隔室的数量以及哪些组件被合并/拆分为隔室,对安全性和性能有重大影响,因此它应该是可配置的。
(P2) 所使用的硬件隔离机制应该是可配置的。存在广泛的隔离机制,具有各种安全性和性能影响。这些应该由用户配置。对于OS开发人员而言,支持新机制不应涉及任何重写/重新设计,而应与实现定义明确的API一样简单。
(P3) 软件硬化和隔离机制应该是可配置的。诸如CFI或软件故障隔离 (SFI) 之类的软件强化技术,以及诸如Rust之类的内存安全语言,以可变的性能成本带来了不同级别的安全性。它们应该选择性地适用于在给定用例中它们最有意义的组件。
(P4) 灵活性不应该以性能为代价。OS运行时性能应类似于在没有灵活性方法的情况下使用任何特定的安全配置所实现的性能。
(P5) 与现有软件的兼容性不应以很高的移植成本来最大程度地采用。
(P6) 应在FlexOS启用的广阔设计空间中引导用户。鉴于其非常大的配置空间,该系统应配备工具,可帮助用户针对给定的用例识别合适的安全/性能配置。
2.2 Challenges and Approach
- P1和P4是考虑在隔离上平衡性能和通用性的问题,通过Unikraft,再加代码转译来实现。(参考文献主要是libOS相关)
- P2和P5是考虑如何在现有系统中引入多种硬件隔离机制,同时降低引入成本。这里引入原文来解释一下:
技术不可知论在userland软件中已经很困难,但是核心内核设施 (中断处理,内存管理,调度) 引入了额外的复杂性,根据底层隔离技术的不同,这些复杂性应该被非常不同地处理。例如,某些技术在保护域之间共享单个地址空间 (例如MPK [15]),而其他技术则使用不相交的地址空间 (例如TEEs [3],EPT)。FlexOS的主要思想是抽象现有的隔离技术,并根据技术确定需要不同处理的内核设施,并设计这些子系统,以最大程度地减少实现新技术时所需的更改。
- P5同时要求减少移植工作量要求。FlexOS应该是扩充了Unikraft的可视化界面(参考工作是安全、性能相关的进程隔离ATC,USENIX Security等)
- P1-P3, P6需要系统引导配置空间。为此FlexOS自带一个安全性概率排名来推荐组合。(没有相关工作可参考)
3. Design an OS with Isolation
FlexOS基于Unikraft实现。它采用类似Unikraft的配置方式。这个例子中将libopenjpg和libredis放在一起。
背景补充:CFI(Control flow integrity)
用途:细粒度CFI严格控制每一个间接转移指令的转移目标,这种精细的检查,在现有的系统环境中,通常会引入很大的开销。而粗粒度CFI则是将一组类似或相近类型的目标归到一起进行检查,以降低开销,但这种方法会降低CFI的保护效果。
背景补充:ASAN
用途:ASAN(Address Sanitizer)是针对 C/C++ 的快速内存错误检测工具,在运行时检测 C/C++ 代码中的多种内存错误。
性能影响:ASan 支持 arm 和 x86 平台,使用 ASan 时,APP 性能会变慢且内存占用会飙升。CPU 开销约为 2 倍,代码大小开销在 50% 到 2 倍之间,内存开销很大,约为 2 倍,具体取决于分配模式。

- LibOS基础:与Unikraft相反,所有库都在同一保护域中,并且任何库都可以直接从另一个库调用函数,在flexos的源代码库中,通过抽象门调用外部函数,并且可以以字节的粒度与外部库共享数据使用抽象代码注释。
- API构建实例化:跨隔室调用是通过在构建时实例化的抽象调用门进行的 (图2中的箭头)。共享数据使用编译器注释进行标记,在构建时用于实例化给定的数据共享策略。与基于链接器的方法不同 [74],FlexOS使用Coccinelle [48,71](一种代码转译技术) 使用源到源转换来执行替换。
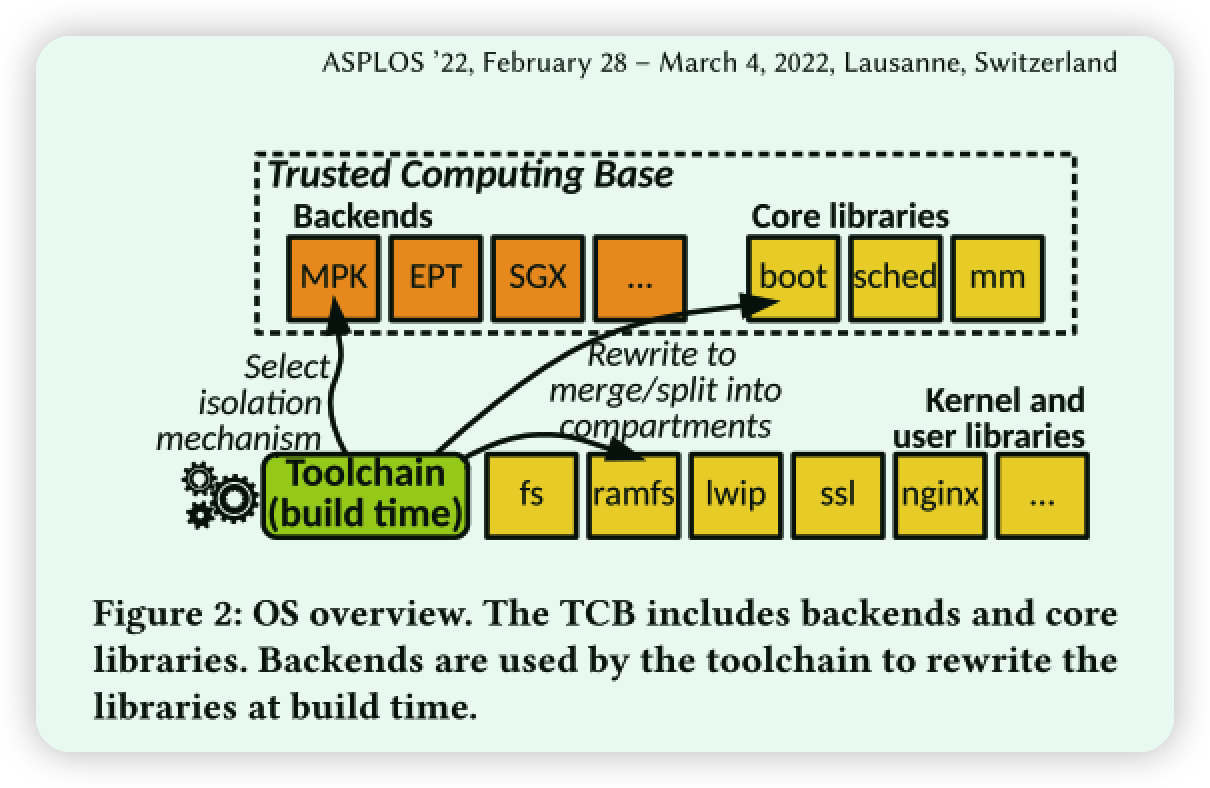
3.1 Compartmentalization API and Transformations
API划分与转化
传统的硬件隔离跨compartment隔离,是通过控制权限转化(SGX/TEE)或者远程调用(ARM TRUSTZONE)。在FlexOS中,隔离机制的唯一要求是
(1) 实现保护域的概念并提供域切换机制
(2) 支持某种形式的共享内存以进行跨域通信。
Call Gates:FlexOS用跨lib调用的方式。它用Call Gates作为占位符。在同compartment就用常规调用(图3 ③‘),否则保护域切换(图3 ③)。具体实现原理参照Csope和Coccinelle。
Data ownership Approach:FlexOS默认将库分配的所有静态和动态数据视为私有数据。然后,与访问控制列表类似,可以将单个变量注释为具有特定库组的分享。实际上,隔离数据共享的最大数量受基础技术的限制。注释是使用关键字 __ share 共享进行的,如图3步骤2所示。这个分隔API本身没有共享变量,而是占位符自动生成。目前这种注释方法是采用生动添加的方式(尽管有很多程序分析上先进的工作)
Build-time Source Transformations:在编译之前,FlexOS的工具链执行源转换,以 (1) 实例化抽象门,(2) 实例化数据共享代码,(3) 生成链接器脚本,以及 (4) 根据后端提供的配方在核心库中生成附加代码。产生的代码量相当可观。例如,工具链为简单的Redis配置自动修改了大约1 KLoC。图3步骤3 给出了移植转换过程的示例。
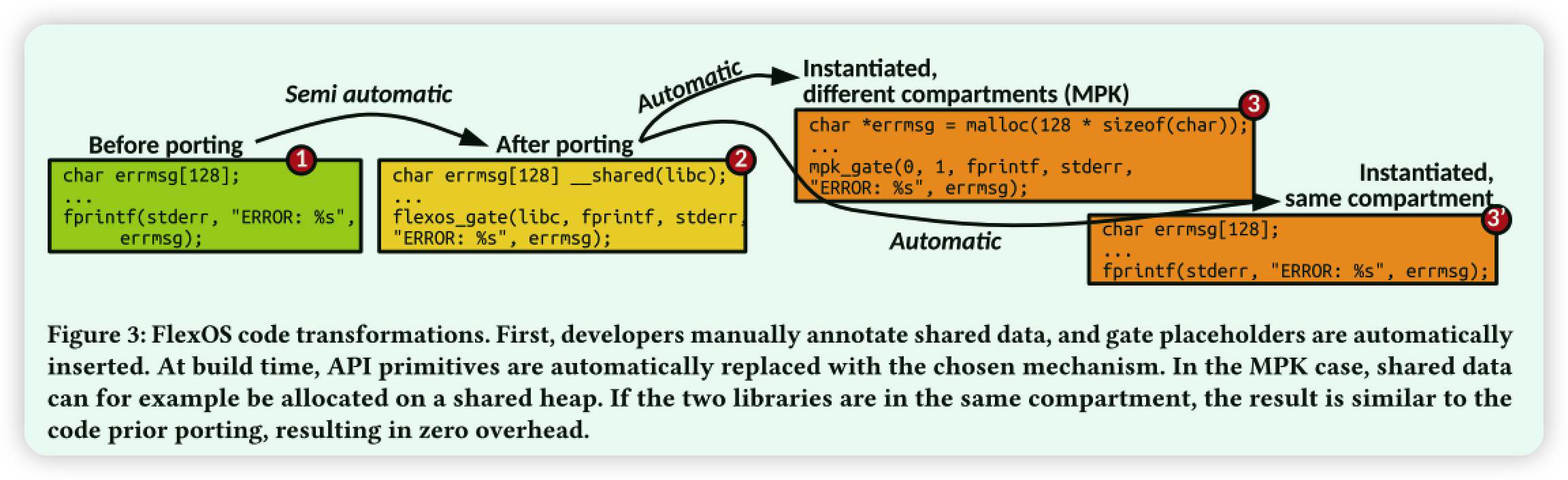
图3:FlexOS代码转换。首先,开发人员手动注释共享数据,并自动插入gate占位符。在构建时,API原语会自动替换为所选的机制。在MPK情况下,例如可以在共享堆上分配共享数据。如果两个库在同一个隔间中,则结果类似于先前移植的代码,从而导致零开销。
3.2 Kernel Backend API
大多数隔离机制都需要更改内核中的一组特定组件。根据技术需要特殊处理的内核设施仅对应于核心库 (请参见图2)。FlexOS将hook API暴露给隔离后端,从而可以轻松地使用后端特定功能扩展核心库。完成以下内容就可以轻松实现代码迁移:
(1) 实现特定机制的门,(2) 实现核心组件的钩子 (见前一段),(3) 实现工具链中的链接器脚本生成,(4) 实现Coccinelle代码转换,(5) 将新创建的后端注册到工具链中。
读者注:这一段算是对各种库进行代码迁移的一个总结,这里的Backend要结合图2,后端包括了MPK,EPT和SGX技术。api就是在图3中flexos_gate -> mpk_gate类似这种转化
3.3 Trusted Computing Base
可信计算库,这里首先列出可能会损害到OS内核的改动(过去的libos):(1) the early boot code, (2) the memory manager, (3) the scheduler, (4) the first-level interrupt handler’s context (5) isolation backend
这些模块被称为可信计算基础 Trusted Computing Base(TCB)。故障或恶意的早期引导代码可能会以不安全的方式设置系统,内存管理器可以操纵页表映射以便自由访问任何隔室的内存,调度器可以操纵睡眠线程的寄存器状态,后端提供不完全隔离等。
这段其实就是在分析哪些是整个系统中安全关注的部分。例如:
- 不同的组件 (例如网络堆栈,解析器库等) 可以被认为是不受信任的并且可能受到损害。
- 硬件和编译器也是TCB的一部分。
- 工具链的其余部分 (包括Coccinelle) 不是TCB的一部分,因为代码包括能够检测无效转换的编译时间检查。
4. Prototype
FlexOS在Unikraft [47] v0.5的顶部展示了FlexOS的原型,带有Intel MPK和EPT后端。对Unikraft内核的修改表示大约3250个LoC: MPK后端的1400、EPT的1000和核心库的850。在用户空间中,对Unikraft工具链的更改表示2300 LoC。我们将用户代码库 (Redis,Nginx,iperf和SQLite) 以及大多数内核组件 (tcp/ip堆栈,调度程序,文件系统等) 移植为隔离组件运行。本节介绍MPK和EPT后端,绘制CHERI后端的草图,并以移植工作作为结尾。
这里在分析的时候,都会根据下面这几方面,进行安全层面的分析。不知道这是不是安全类分析文章的固定规则。
- xxx Gates
- Data ownership
- Data Shadow Stacks(可选)
- Control Flow Integrity 控制流完整性
4.1 Intel MPK Isolation Backend
参考文章:https://mstmoonshine.github.io/p/intra-unikernel-mpk/
在VEE’20上Intra-Unikernel Isolation with Intel Memory Protection Keys这篇工作,当时就已经有探讨将MPK引入到Unikernel的尝试,来实现Unikernel内部的隔离性
背景补充:利用 MPK 我们可以进行线程级别的页权限管理,并且无需修改页表配置。MPK 的目标是提供每个 core 独立的内存访问权限管理。使用 MPK 之前,首先要将内存分组,最多分成 16 组。这 16 组的二进制编号 0b0000 ~ 0b1111 被称为 protection key。MPK 使用 x86 page table 中的 4 个 unused bits 来 label 分组信息:比如,如果这 4 个 bits 被设置成 0b1001,那么这个 page 就属于第 9 组。
分组之后,MPK 的使用就无需页表参与了。CPU 的每个 core 都有一个 32-bit 的寄存器(PKRU)来储存当前 core 对每个组的访问权限。PKRU 寄存器中包含 16 对 bit pair,对应 16 个 page group,每个 pair 包含两个 bit, 分别代表 R / W 权限。每个 pair 的取值对应三种可能的权限 (0, 0): read/write,(1, 0): read-only,(x, 1): no-access。如下图所示:
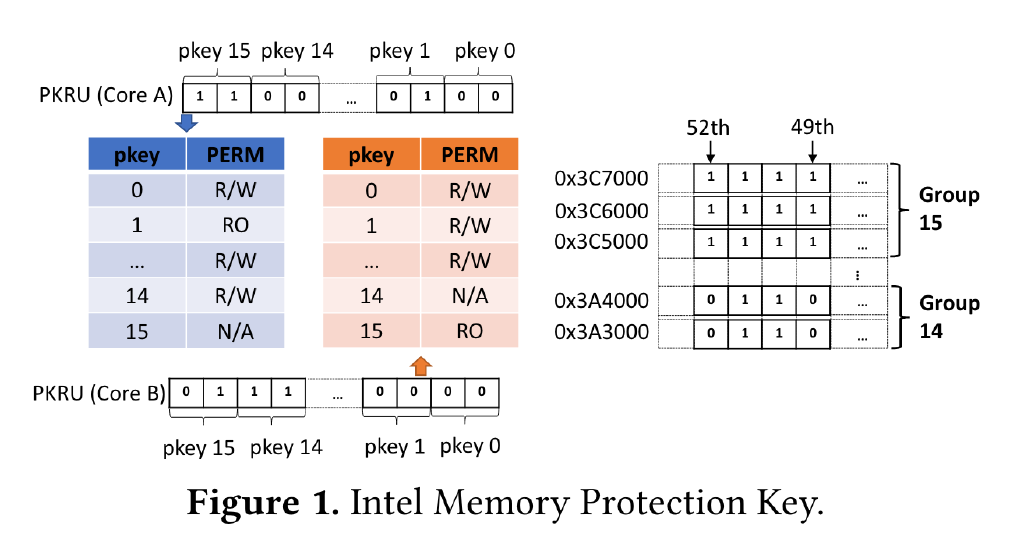
MPK 能够提供的安全性其实是相当有限的,那要它还有什么用呢?MPK 的优点在于快,进行一次 PKRU 读写只需要 20 cycles 左右,相比进行一次 context switch 来说,PKRU 的切换非常快速。因此 MPK 的目标并不是去防御尽可能多的攻击,而是以非常廉价的开销去防御一些特定类别的攻击。
MPK是Intel CPU级别的一种低开销内存隔离技术。****MPK利用页表条目中未使用的位来存储内存保护密钥,从而支持多达16个保护域。然后,PKRU寄存器存储当前线程的保护键权限。在每次内存访问时,MMU将目标页面的键与PKRU进行比较,并在权限不足的情况下触发页面错误。FlexOS将每个隔离舱与一个保护密钥相关联,并为用于通信的共享域保留一个密钥。如果映像包含的隔离舱少于15个,FlexOS将剩余的密钥用于受限隔离舱组之间的其他共享域。
- MPK Gates:为提高灵活性,FlexOS提供了两种不同的MPK门实现方案。主要的一个提供了完全的空间安全性,类似于HODOR [32]。门电路保护寄存器组,并且每个隔离舱(compartment)的每个线程使用一个调用堆栈。每个隔离舱都有一个堆栈注册表,该注册表将线程映射到其本地隔离舱堆栈,从而可以快速、安全地切换调用堆栈。在域转换时,门电路(1)保存当前域的寄存器组,(2)清除寄存器,以及(3)加载函数自变量。然后(4)保存当前堆栈指针,(5)切换线程许可,(6)切换堆栈,最后(7)执行调用指令。函数返回后,将反向执行操作。第二种方式是在区间之间共享堆栈和寄存器集,类似ERIM(Usenix Security’19),低开销。
- Data Ownership:FlexOS的MPK映像在每个隔离舱中具有一个数据、只读数据和bss部分,用于存储私有隔离舱静态数据。在启动时,引导代码使用隔离舱的保护密钥保护这些部分。
每个隔离舱compartment都有一个私有堆,一个共享堆用于通信。我们的原型对所有共享分配使用单个共享堆,但这不是基本限制。堆栈分配稍微复杂一些。现有工作将共享栈分配转换为共享堆分配[6,32,44,都是MPK技术的扩展文章]。从性能的角度来看,这种方法代价高昂:对于现代分配器,快速路径上的分配+释放通常花费30-60个周期,并且在慢速路径上花费多达数千个周期[40]。这与整个域转换的开销一样大,而且对于单个共享堆栈变量也是如此。虽然FlexOS支持栈到堆的转换,但我们提出了另一种解决此问题的方法,即数据影子栈(Data Shadow Stacks)。
- Data Shadow Stacks(DSS):栈stack分配比堆heap分配快得多,因为编译器能够在编译时执行簿记(bookkeeping)。在运行时,只需要一个推送指令,从而导致恒定的低成本。图4所示的数据阴影堆栈(DSS)利用这种簿记工作进行共享堆栈分配。
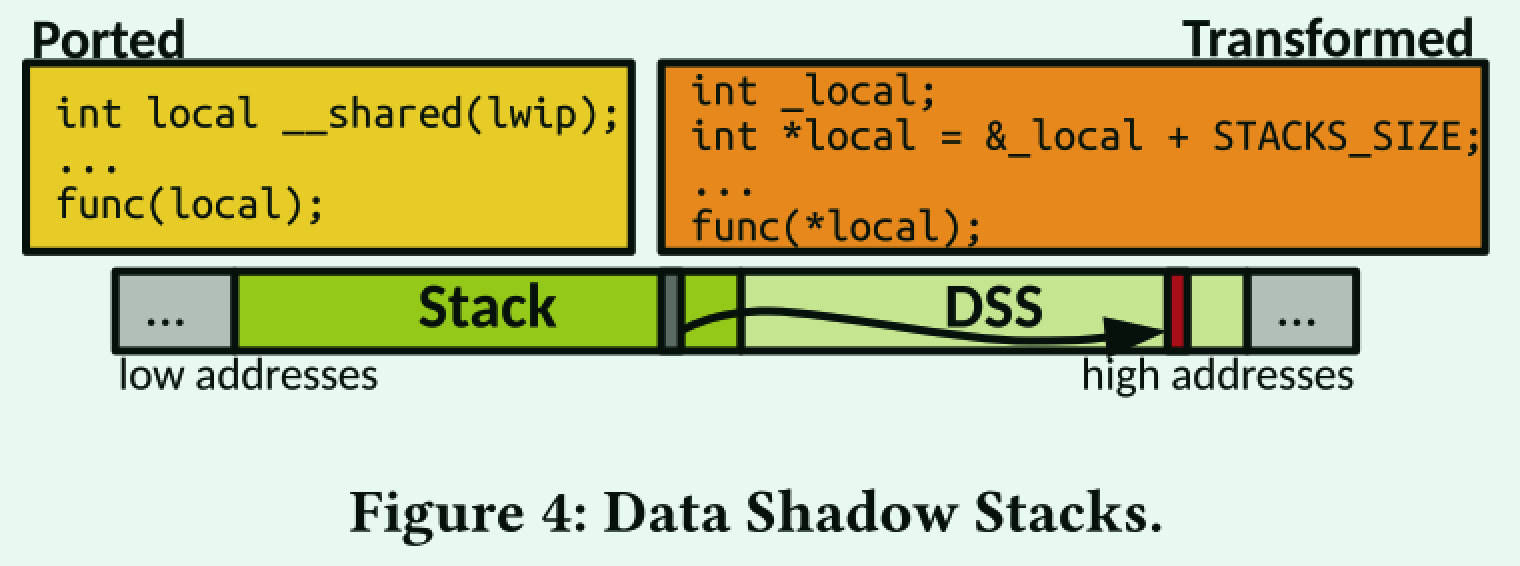
使用DSS时,线程的堆栈大小通常会翻倍,内存复制了一份。高地址位对应于DSS,放在共享域中。低地址位是传统的堆栈,保留在隔离舱的私有域中。对于每个共享变量x,我们将x的影子定义为&x + STACK_SIZE。因此,在堆栈上为共享变量分配空间透明地在DSS中分配影子变量。编译前,工具链会将共享堆栈变量的每个引用替换为共享域中的shadow *(&var + STACK_SIZE)。
DSS上的分配比共享堆上的分配快得多,因为DSS的簿记开销为空(堆栈速度),并且引用的局部性很高。其代价是内存使用量相对较小的增加(堆栈是原来的两倍)。DSS机制适用于任何支持共享内存的隔离机制,并且与常见的堆栈保护机制兼容。
Control Flow Integrity。英特尔MPK不提供执行保护。因此,如果一个隔离舱受损,攻击者进入另一个隔离舱,则不会直接发生故障。MPK后端能够提供某种形式的CFI,确保只能在定义良好的点进入隔离舱。这种能力是3.1中描述的门硬编码的结果。如果一个隔离舱的控制流被破坏,攻击者直接ROP到另一个隔离舱𝑐,那么如果访问任何本地数据,系统肯定会崩溃𝑐。
4.2 EPT/VM Backend
提升内存虚拟化的性能,Intel推出了EPT(Enhanced Page Table)技术。这部分非常重要,涉及到了虚拟机间共享内存数据。
EPT背景科普:参考链接https://zhuanlan.zhihu.com/p/41467047
虚拟化技术引入后,内存地址空间更加复杂了,客户机(Guest)和宿主机(Host)都有自己的地址空间。显而易见,Guest负责GVA(Guest Virtual Address)和GPA(Guest Physical Address)之间的转换;Host负责HVA和HPA之间的转换;而GPA和HPA之间的转换,就需要虚拟化层(Hypervisor)辅助了,这个过程一般被称为内存虚拟化。
早期的X86 CPU硬件辅助虚拟化能力很不完善,所以Hypervisor需要通过软件实现内存虚拟化。因此,Hypervisor为每个客户机每套页表额外再维护一套页表,通常也称为影子页表。
影子页表也带来了下面的主要缺点:
- Hypervisor 需要为每个客户机的每个进程的页表都要维护一套相应的影子页表,这会带来较大内存上的额外开销;
- 客户在读写CR3、执行INVLPG指令或客户页表不完整等情况下均会导致VM exit,这导致了内存虚拟化效率很低;
- 客户机页表和和影子页表的同步也比较复杂;
为了简化内存虚拟化的实现,以及提升内存虚拟化的性能,Intel推出了EPT(Enhanced Page Table)技术,即在原有的页表基础上新增了EPT页表实现另一次映射。这样,GVA-GPA-HPA两次地址转换都由CPU硬件自动完成。
虚拟化已在许多工作中用于支持内核内的隔离 [53,67,68,84]。与MPK相比,硬件辅助虚拟化得到了广泛的支持,并提供了强大的安全保证,代价是更高的开销。EPT后端是一种极端情况; 隔间不共享ASes并在不同的vcpu上运行。它表明FlexOS能够在通用API下满足非常不同的机制。
Flexos的EPT后端每个隔室生成一个VM映像,每个映像都包含TCB (引导代码,调度程序,内存管理器,后端运行时) 和隔室的库。通信使用基于共享内存的RPC实现。我们的原型在修补的QEMU/KVM上运行,以支持轻量级的VM间共享内存 (小于90 LoC)。
- EPT Gates:域转换后,调用者将函数指针和参数放置在预定义的内存共享区域中。所有其他虚拟机忙碌等待,直到他们注意到一个RPC请求,检查该函数是一个合法的API入口点,执行该函数并将返回值放置在共享内存的预定义区域中。为了支持多线程负载,每个RPC服务器都维护一个用于服务RPC的线程池。使用函数指针代替抽象例程标识符简化了RPC服务器的非编组操作,并且不会阻止RPC服务器检查指针以确保其是合法的入口点。这种优化是可能的,因为所有隔间都是同时构建的,因此所有地址都是已知的。
- Data Ownership: EPT后端依靠**共享内存区域来跨vm共享数据 (静态和动态)**。区域总是映射在不同隔间中的相同地址,以便共享结构中的指针保持有效。每个VM都管理其共享内存区域的自己部分,以避免复杂的多线程簿记的需要。
- Control Flow Integrity:EPT后端能够提供比MPK后端更强的CFI形式,从而确保只能在定义明确的点处离开和进入隔间。实际上,RPC服务器可以在入口处控制执行的函数是合法的,并且在没有RPC调用的情况下,隔室无法执行其他隔室的代码。
4.3 Supporting More Isolations
探讨了支持CHERI ISA for ARMv8。只是展望,没有具体篇幅。
4.4 Porting Effort
这里探讨了引入安全转化机制后对原项目的影响,主要是共享变量的增减。
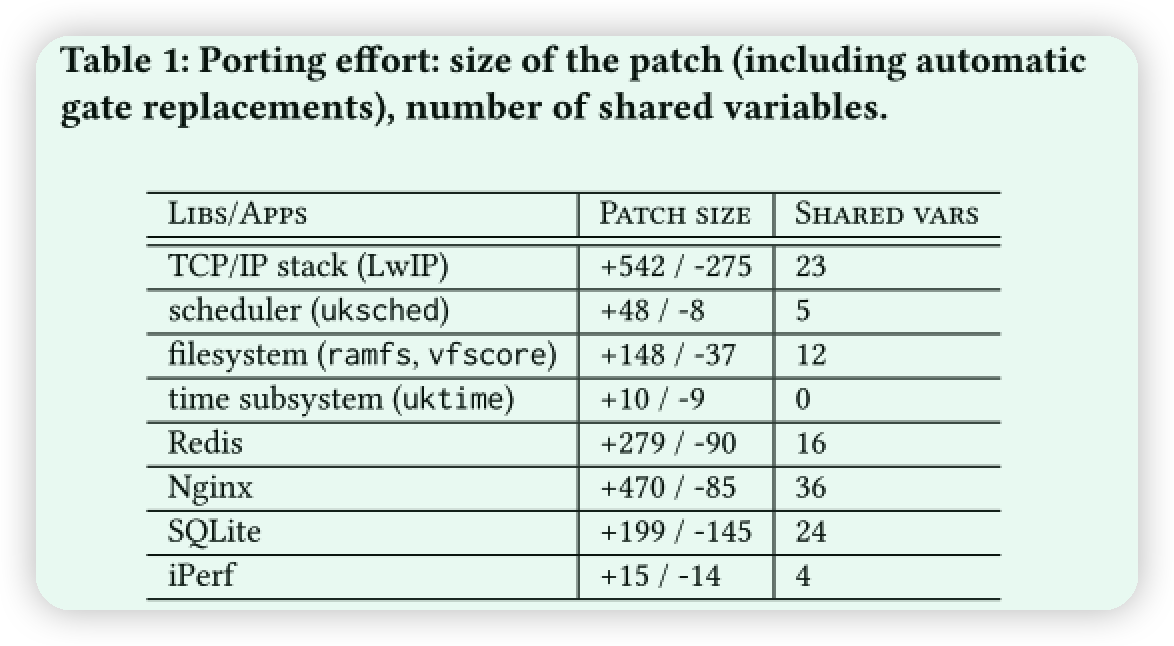
移植过程包括两个阶段: 呼叫门插入 (自动) 和共享数据注释 (手动)。接着分析了这种移植对具体应用的影响,尤其分析了文件系统相关由于代码耦合对移植难度增加的分析。
4.5 Software Hardening
其它增强手段来对性能优化,不重要略过
5. EXPLORATION WITH PARTIAL SAFETY ORDERING
自动化安全配置算法。
在本节中,我们介绍了一种设计空间探索技术,即部分安全排序,旨在通过对庞大的设计进行细分来指导用户针对给定用例进行合适的配置
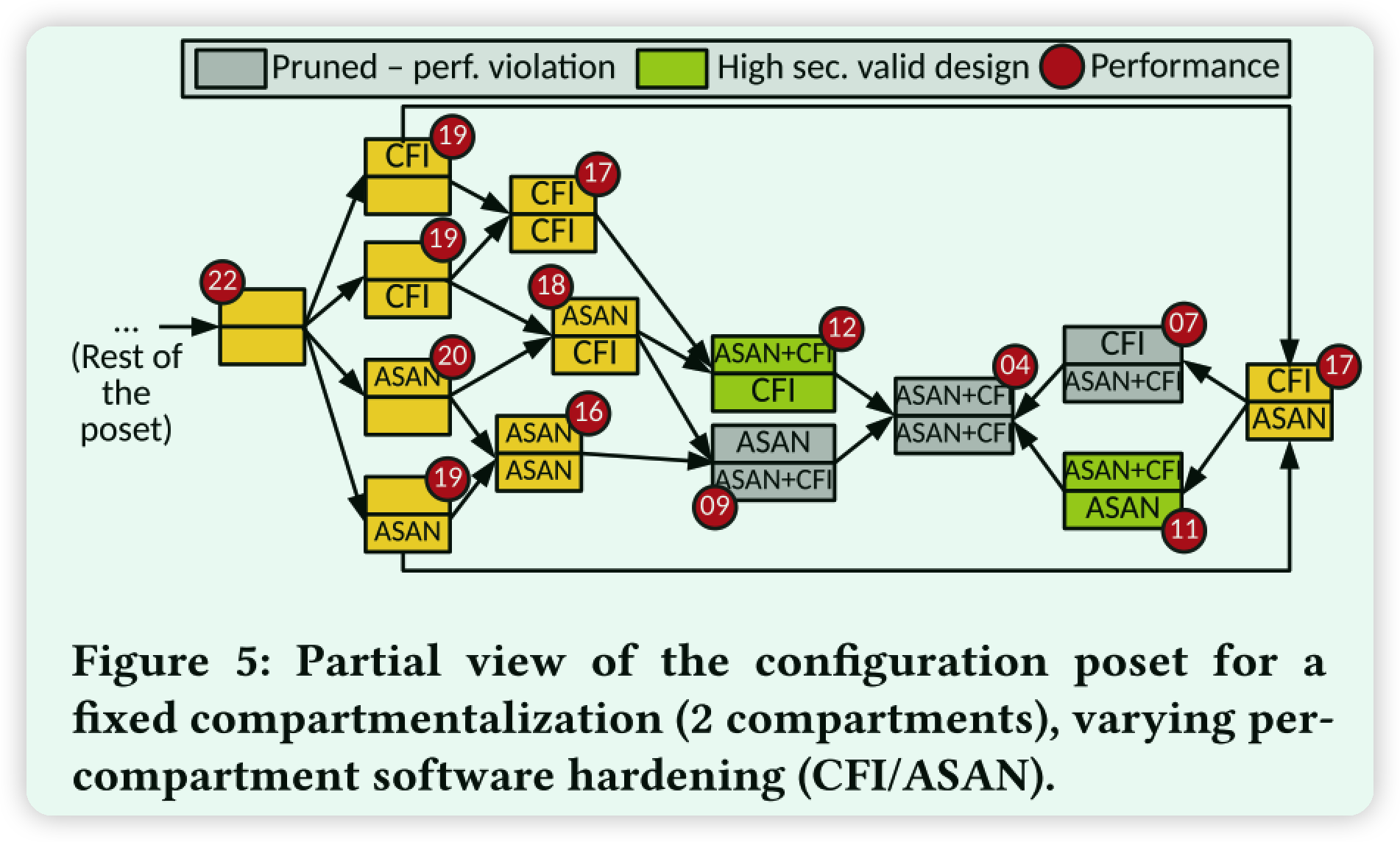
就这个图能看出来就是情况枚举,然后将不可行方案剪枝。绿色应该是最后要保留的方案。
首先明确不可能找到一个绝对安全的配置空间,因为难以量化安全性。
CFI和ASAN都是硬件加强机制。
图5给出了与具有2个隔室的分隔策略的固定选择相对应的配置姿势的子集,隔离机制和数据共享策略。poset的这个子集表示最后一个功能 (软件硬化) 的变化,为了简单起见,我们仅假设CFI和ASAN。每个配置由一个节点描述,该节点指示对于两个隔室中的每个隔室应用了哪种硬化机制: none,CFI,ASAN和CFI ASAN。我们构造了部分描述在图5上的poset,假设安全性随1) 隔室数量的增加而增加; 2) 数据隔离 (隔离与共享堆栈,每对通信隔室的专用共享内存区域与可从任何地方访问的共享区域等);3) 可堆叠的软件硬化; 以及4) 隔离机构的强度。
实践中的部分安全秩序。实际上,用户向工具链提供测试一下脚本 (例如,Nginx的wrk) 和性能预算 (例如,至少500k req./s)。用户可以根据自己的需求自由定义他们可能认为合适的性能: 应用程序吞吐量,尾部延迟,运行时间等。任何指标都是合适的,只要它在配置和运行之间保持可比。有了这个,工具链就会生成未标记的poset。然后,它通过自动测量每个配置的性能来标记它。工具链不必运行所有配置: 假设性能单调下降,一旦达到阈值,它就可以安全地停止评估路径。在实践中,我们观察到这极大地限制了组合爆炸。结果是针对给定预算的一组最安全的配置,用户可以使用该配置来选择最适合给定用例的配置。最终,我们希望此过程能够显着减少设计空间,并允许用户做出明智且相对轻松的选择。
6. Evaluation
性能:吞吐量、安全
实验应用:Redis,SQLite,Nginx
比较对象:其它libos
6.1 Design Space Exploration:Redis, Nginx
使用Wayfinder [38]基准测试平台为Redis和Nginx自动生成并运行了大量的配置。我们将隔离机制固定到带有DSS的MPK,并更改:隔离舱数量(1-3)、隔离组件(TCP/IP堆栈、libc、调度程序、应用程序)以及每个隔离舱的软件强化(堆栈保护器、UBSan和KASan),总共2x 80个配置。
这部分就是去找安全和性能的tradeoff,硬化+隔离技术是对性能有损伤的。作者对两个应用不同的安全组合对性能的影响进行了讨论

图6:Redis(上图)和Nginx(下图)在一系列配置下的性能。组件位于左侧。可以为每个组件启用[·]或禁用[]软件硬化。白色/蓝色/红色表示组件放入的隔室。MPK和DSS可实现隔离。
6.2 Partial Safety Ordering
我们在图6中的Redis数据上应用了这种技术。我们构建了图8中的偏序集,其中每个节点都是Redis配置,即图6中的一列。节点的颜色强度表示配置的性能,黑色表示最快(1.2M req/s),较慢的配置逐渐变为白色(纯白表示292 K req/s)。最快的配置是没有隔离和强化的配置(图8中的A)。图中心的其他节点表示添加的隔室,仍然没有强化:将调度程序B、lwip C或Redis+newlib D与系统的其余部分分开,以及3个隔离舱场景E。从这5个基本的划分策略出来5个分支。每个分支中的节点表示每个组件软件强化的各种组合。节点的颜色变化表示创建新的隔离舱和在组件上堆叠软件加固对性能的不同影响。
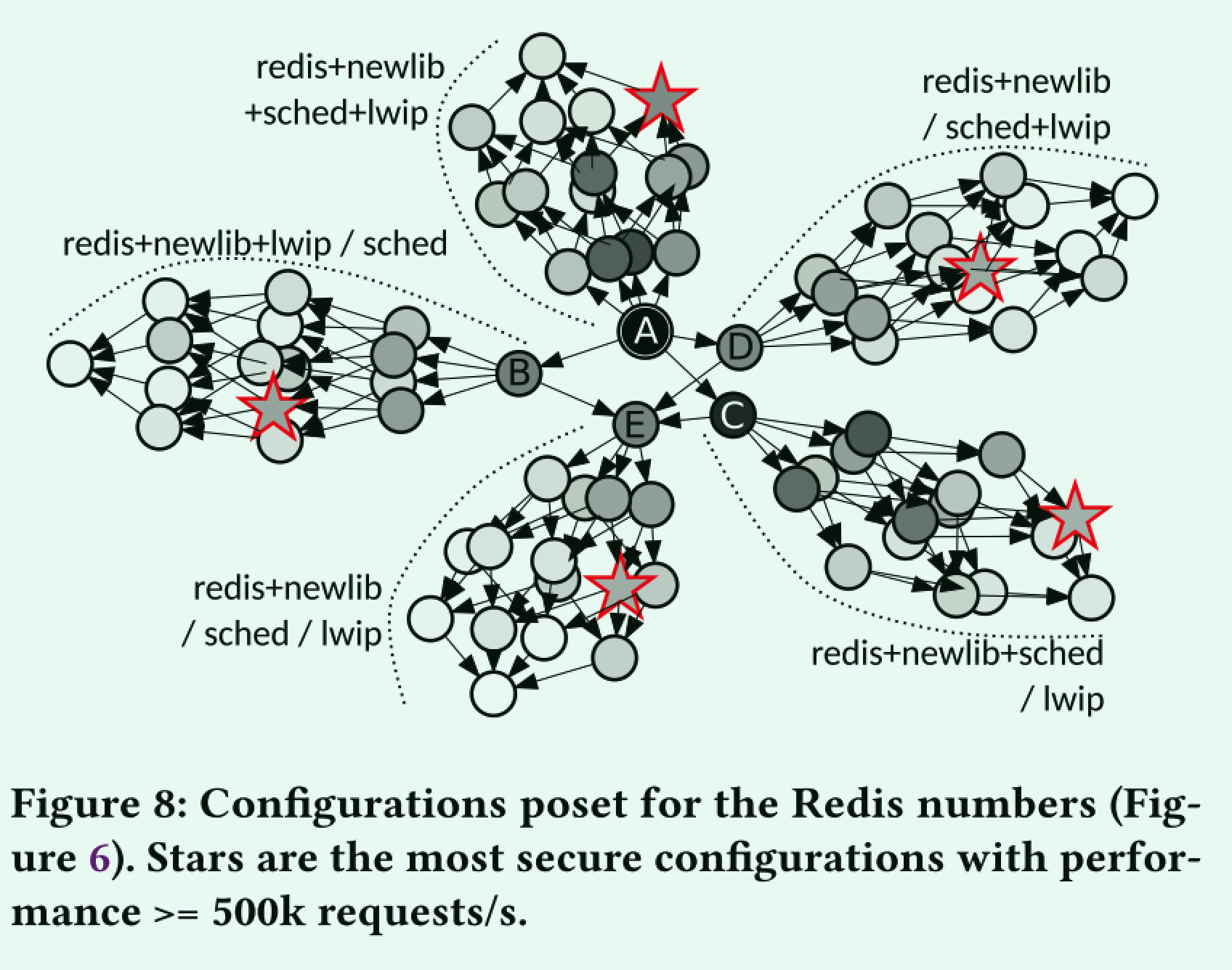
我们将最低要求性能设置为500 K req/s,并让部分安全排序确定满足该约束的最安全配置,如图8中的星号所示。在这种情况下,该技术可以将配置空间从80个削减到5个配置,帮助用户容易地挑选最合适的一个。
读者评价
这篇文章就是两个亮点:
- 将安全隔离做到unikraft里,做性能-安全的trade-off,并在代码层面做了转译。
- 自动化安全配置搜索,就是安全配置组合,当安全隔离加多了导致性能降低到阈值以下,剪枝这种方案。
- 这篇已经初步提到将多个Unikernel来集中实现一个功能,值得参考借鉴