IB 驱动源码
Doorbell机制
首先需要了解一个完整的发送过程,才能确定门铃机制在那个过程中起作用。
下图是一张简略的IB发送数据流程。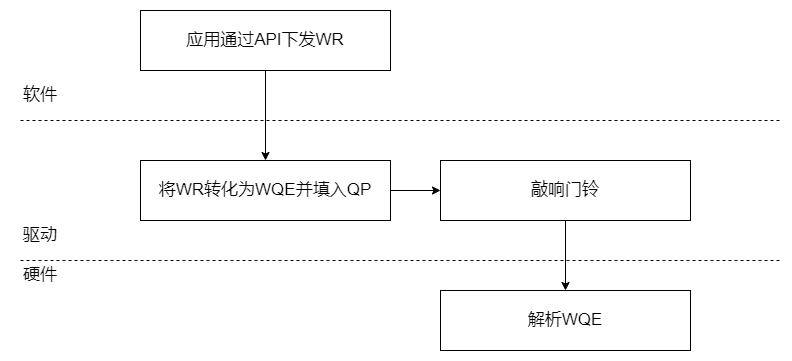
在图中可以看到,门铃主要是起到通知硬件的作用。类似于DMA过程中告诉CPU,数据已经存取完毕的过程。
post_send函数主要完成了下列操作。
- 从QP Buffer获取下一个WQE的内存地址。
- 解析WR的内容,填入到WQE中。
- 填写完毕,敲响Doorbell,doorbell是一个地址。
- 硬件从QP中取出WQE,解析WQE。
- 硬件取出数据,组包,发送数据。
查阅资料发现,doorbell地址是在ibv_open_device函数中映射过来的。下发WR
主要是关注post_send函数将WR放哪去了。可以看到用户态下是直接调用qp的post_send操作,在这里我推测实际与驱动绑定还是在内核态下完成的。所以我们只用看内核态下的post_send函数,流程应该是一样的。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15// 内核
int mlx5_ib_post_send(struct ib_qp *ibqp, const struct ib_send_wr *wr,
const struct ib_send_wr **bad_wr, bool drain)
// 用户
static inline int ibv_post_send(struct ibv_qp *qp, struct ibv_send_wr *wr,
struct ibv_send_wr **bad_wr)
{
return qp->context->ops.post_send(qp, wr, bad_wr);
}
mlx5_ib_post_send的代码很长,其中发现了一个叫做mlx5r_finish_wqe的调用,这段应该是完成了对wqe的封装,准备塞入到QP中。进入到mlx5r_finish_wqe函数中。1
2
3
4
5
6
7
8
9
10// 取下一个WQE的内存地址
err = begin_wqe(qp, &seg, &ctrl, wr, &idx, &size, &cur_edge,
nreq);
mlx5r_finish_wqe(qp, ctrl, seg, size, cur_edge, idx, wr->wr_id,
nreq, fence, mlx5_ib_opcode[wr->opcode]);
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55void mlx5r_finish_wqe(struct mlx5_ib_qp *qp, struct mlx5_wqe_ctrl_seg *ctrl,
void *seg, u8 size, void *cur_edge, unsigned int idx,
u64 wr_id, int nreq, u8 fence, u32 mlx5_opcode)
{
u8 opmod = 0;
ctrl->opmod_idx_opcode = cpu_to_be32(((u32)(qp->sq.cur_post) << 8) |
mlx5_opcode | ((u32)opmod << 24));
ctrl->qpn_ds = cpu_to_be32(size | (qp->trans_qp.base.mqp.qpn << 8));
ctrl->fm_ce_se |= fence;
if (unlikely(qp->flags_en & MLX5_QP_FLAG_SIGNATURE))
ctrl->signature = wq_sig(ctrl);
qp->sq.wrid[idx] = wr_id;
qp->sq.w_list[idx].opcode = mlx5_opcode;
qp->sq.wqe_head[idx] = qp->sq.head + nreq;
qp->sq.cur_post += DIV_ROUND_UP(size * 16, MLX5_SEND_WQE_BB);
qp->sq.w_list[idx].next = qp->sq.cur_post;
/* We save the edge which was possibly updated during the WQE
* construction, into SQ's cache.
*/
seg = PTR_ALIGN(seg, MLX5_SEND_WQE_BB);
qp->sq.cur_edge = (unlikely(seg == cur_edge)) ?
get_sq_edge(&qp->sq, qp->sq.cur_post &
(qp->sq.wqe_cnt - 1)) :
cur_edge;
}DoorBell
Hardware doorbell本身是设备的一个MMIO寄存器,一旦写这个地址硬件就能感知。
既然在post_send函数中,将WR对应的WQE塞入到了指定的QP中。那么可以去QP中看看DoorBell是如何起作用的。
但是这部分的代码实在过于复杂,并没有发现确定的敲响门铃的地方,只发现了相关的蛛丝马迹。
在drivers/InfiniBand/hw/mlx5/doorbell.c文件中只有以下两个函数出现。这是两个功能相反的函数,我们只需要看mlx5_ib_db_map_user做什么就行。1
2
3
4
5int mlx5_ib_db_map_user(struct mlx5_ib_ucontext *context, unsigned long virt,
struct mlx5_db *db);
void mlx5_ib_db_unmap_user(struct mlx5_ib_ucontext *context, struct mlx5_db *db);从该函数细节来看,该函数主要完成了将db和qp进行绑定的操作。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87int mlx5_ib_db_map_user(struct mlx5_ib_ucontext *context, unsigned long virt,
struct mlx5_db *db)
{
struct mlx5_ib_user_db_page *page;
int err = 0;
mutex_lock(&context->db_page_mutex);
list_for_each_entry(page, &context->db_page_list, list)
if ((current->mm == page->mm) &&
(page->user_virt == (virt & PAGE_MASK)))
goto found;
page = kmalloc(sizeof(*page), GFP_KERNEL);
if (!page) {
err = -ENOMEM;
goto out;
}
page->user_virt = (virt & PAGE_MASK);
page->refcnt = 0;
page->umem = ib_umem_get(context->ibucontext.device, virt & PAGE_MASK,
PAGE_SIZE, 0);
if (IS_ERR(page->umem)) {
err = PTR_ERR(page->umem);
kfree(page);
goto out;
}
mmgrab(current->mm);
page->mm = current->mm;
list_add(&page->list, &context->db_page_list);
found:
db->dma = sg_dma_address(page->umem->sgt_append.sgt.sgl) +
(virt & ~PAGE_MASK);
db->u.user_page = page;
++page->refcnt;
out:
mutex_unlock(&context->db_page_mutex);
return err;
}
继续看一下mlx5_ib_db_map_user在哪里被使用过,搜索一下应用。mlx5_ib_db_map_user该函数被调用的地方全都在创建相关qp的时候,因此是将db和qp进行绑定然后在driver/infiniband/hw/mlx5/wr.c文件中有这样的代码。从函数的命名来看,ring_db的含义就是敲响门铃的意思。先不管函数是怎么实现的,该函数的功能就是准备好了wqe,这时候敲响门铃通知硬件。1
2
3
4
5
6
7
8
9
10
11static int _create_user_qp(struct mlx5_ib_dev *dev, struct ib_pd *pd,
struct mlx5_ib_qp *qp, struct ib_udata *udata,
struct ib_qp_init_attr *attr, u32 **in,
struct mlx5_ib_create_qp_resp *resp, int *inlen,
struct mlx5_ib_qp_base *base,
struct mlx5_ib_create_qp *ucmd);在mlx5_post_send函数的结尾处,在上次提过,该函数是硬件相关的一个post_send函数。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49void mlx5r_ring_db(struct mlx5_ib_qp *qp, unsigned int nreq,
struct mlx5_wqe_ctrl_seg *ctrl)
{
struct mlx5_bf *bf = &qp->bf;
qp->sq.head += nreq;
/* Make sure that descriptors are written before
* updating doorbell record and ringing the doorbell
*/
wmb();
qp->db.db[MLX5_SND_DBR] = cpu_to_be32(qp->sq.cur_post);
/* Make sure doorbell record is visible to the HCA before
* we hit doorbell.
*/
wmb();
mlx5_write64((__be32 *)ctrl, bf->bfreg->map + bf->offset);
/* Make sure doorbells don't leak out of SQ spinlock
* and reach the HCA out of order.
*/
bf->offset ^= bf->buf_size;
}在另外一个post_send函数中,结尾也出现了类似的调用。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23int mlx5_ib_post_send(struct ib_qp *ibqp, const struct ib_send_wr *wr,
const struct ib_send_wr **bad_wr, bool drain)
{
// 省略
out:
if (likely(nreq))
mlx5r_ring_db(qp, nreq, ctrl);
spin_unlock_irqrestore(&qp->sq.lock, flags);
return err;
}虽然整个RDMA驱动中,存在很多个post_send函数,但到最终的post_send函数,就会敲响该门铃。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51static int mlx5r_umr_post_send(struct ib_qp *ibqp, u32 mkey, struct ib_cqe *cqe,
struct mlx5r_umr_wqe *wqe, bool with_data)
{
// 省略
spin_lock_irqsave(&qp->sq.lock, flags);
err = mlx5r_begin_wqe(qp, &seg, &ctrl, &idx, &size, &cur_edge, 0,
cpu_to_be32(mkey), false, false);
if (WARN_ON(err))
goto out;
qp->sq.wr_data[idx] = MLX5_IB_WR_UMR;
mlx5r_memcpy_send_wqe(&qp->sq, &cur_edge, &seg, &size, wqe, wqe_size);
id.ib_cqe = cqe;
mlx5r_finish_wqe(qp, ctrl, seg, size, cur_edge, idx, id.wr_id, 0,
MLX5_FENCE_MODE_INITIATOR_SMALL, MLX5_OPCODE_UMR);
mlx5r_ring_db(qp, 1, ctrl);
out:
spin_unlock_irqrestore(&qp->sq.lock, flags);
return err;
}
但是敲响门铃后的硬件解析WQE,还没有发现。ib中的内存管理
这部分主要是想看一下wr中指示的数据存放地址是如何通过RDMA技术传输的。MR
MR,memory region,用于解决内存地址虚实映射和保护的问题。
MR是RDMA软件在内存中划定的一片区域,用于存放数据。用户必须通过IB提供的API才允许访问MR,并且MR需要提取申请。
实际上,MR只是一块特殊的内存区域。
引入MR主要是为了解决以下两个问题。
- RDMA网卡如何将VA转化为PA。
- RDMA网卡如何保证违法的VA不会被访问。
VA->PA
在CPU中,VA->PA是通过MMU等转化机制完成的。在RDMA中,APP下发的WR中的地址都是VA,无论是本地地址还是远程地址。因此在注册MR的过程中,硬件会在内存中注册一个VA->PA的映射表。并且访问该映射表是有RDMA硬件完成,不需要对应的CPU参与。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49struct ib_rdma_wr {
struct ib_send_wr wr;
u64 remote_addr;
u32 rkey;
};
struct ib_send_wr {
struct ib_send_wr *next;
union {
u64 wr_id;
struct ib_cqe *wr_cqe;
};
struct ib_sge *sg_list;
int num_sge;
enum ib_wr_opcode opcode;
int send_flags;
union {
__be32 imm_data;
u32 invalidate_rkey;
} ex;
};
struct ib_sge {
u64 addr;
u32 length;
u32 lkey;
};
查阅资料发现,在RDMA中,是通过IOVA访问地址的。
IOVA是IO的虚拟地址,DMA设备可以通过IOMMU将IOVA转化为真实的PA。
实际上,在RDMA中,需要先将VA转化为IOVA。在mlx5驱动中,使用MTT(Memory Translation Table)来存放VA-IOVA的映射。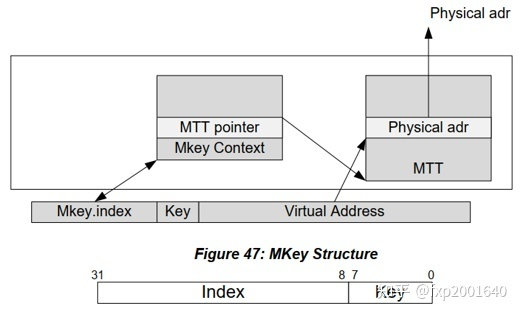
这里直接看到查看populate_mtts被调用的地方。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31static void populate_mtts(struct mlx5_vdpa_direct_mr *mr, __be64 *mtt)
{
struct scatterlist *sg;
int nsg = mr->nsg;
u64 dma_addr;
u64 dma_len;
int j = 0;
int i;
for_each_sg(mr->sg_head.sgl, sg, mr->nent, i) {
for (dma_addr = sg_dma_address(sg), dma_len = sg_dma_len(sg);
nsg && dma_len;
nsg--, dma_addr += BIT(mr->log_size), dma_len -= BIT(mr->log_size))
mtt[j++] = cpu_to_be64(dma_addr);
}
}klm_pas_mtt的定义如下,1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25static int create_direct_mr(struct mlx5_vdpa_dev *mvdev, struct mlx5_vdpa_direct_mr *mr)
{
// 省略
populate_mtts(mr, MLX5_ADDR_OF(create_mkey_in, in, klm_pas_mtt));
err = mlx5_vdpa_create_mkey(mvdev, &mr->mr, in, inlen);
kvfree(in);
if (err) {
mlx5_vdpa_warn(mvdev, "Failed to create direct MR\n");
return err;
}
return 0;
}这里可以挖掘的地方还很多,例如MTT是如何组织数据的。或者是MTT将被存放于内存的哪个区域等,都是日后可以钻研的点。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45struct mlx5_ifc_create_mkey_in_bits {
u8 opcode[0x10];
u8 uid[0x10];
u8 reserved_at_20[0x10];
u8 op_mod[0x10];
u8 reserved_at_40[0x20];
u8 pg_access[0x1];
u8 mkey_umem_valid[0x1];
u8 reserved_at_62[0x1e];
struct mlx5_ifc_mkc_bits memory_key_mkey_entry;
u8 reserved_at_280[0x80];
u8 translations_octword_actual_size[0x20];
u8 reserved_at_320[0x560];
u8 klm_pas_mtt[][0x20];
};违法的VA
可以通过违法的VA,访问到不被允许的PA。因此在MR中引入key对访存进行鉴权。key分为l_key(Local Key)和r_key(Remote Key)。用户保证RDMA Write过程中对两边地址的保护。
这部分可以看到ib_mr结构体的成员。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16struct ib_mr {
struct ib_device *device;
struct ib_pd *pd;
u32 lkey;
u32 rkey;
u64 iova;
u64 length;
// 省略
};防止换页
现代CPU的内存管理中,页表是经常会被换入换出的。一旦换出,那么原先存在的VA->PA映射就失去作用了。
因此MR还有一个作用就是将这篇内存区域固定在内存中,这个动作被形象地称为pin。
在这部分,我们可以先看看注册mr是如何进行的。
如果从用户态的ibv_reg_mr()函数出发,通过ABI命令进入到内核,最终会落入到网卡相关的函数mlx5_ib_reg_user_mr()函数中,因此我们直接看mlx5_ib_reg_user_mr函数即可。
而mlx5_ib_reg_user_mr函数最终调用了create_real_mr函数。
在Linux中,可以通过mlock函数锁住内存页,但是在整个ibv_reg_mr调用路径中,均未发现mlock的调用。