RDMA内核态Verbs学习
- 本文参考了知乎博主Savir创建的知乎RDMA专栏。
- 本文还参考了知乎博主围城的博客内容。
- 本文阅读的Linux内核版本为6.0.1。
内核态API与用户态API
Verbs API是一组用于使用RDMA服务的接口。Verbs API向用户提供了有关RDMA的一切功能,包括注册MR, 创建QP等操作。
在Linux中,Verbs API功能由用户态的rdma-core和内核中的Kernel RDMA Subsystem系统。其中分别以ibv_和ib_作为前缀区分。
RDMA希望数据通路上的调用尽可能绕开内核,而控制面上则需要在内核做出一定量的工作,因此就存在部分的内核态API。RDMA发送基本过程
基本概念
- WQ : Work Queue。WQ是存储工作请求的队列。
- WQE : Work Queue Element。WQE是WQ存放的元素,涉及到具体的意义。WQ是一份“任务书”。任务通常是由软件下达给硬件的。
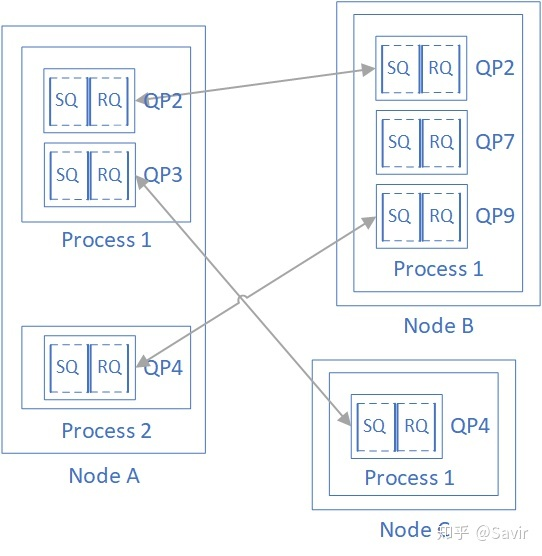
- QP : Queue Pair。一对WQ,通信过程需要两端,QP是发送队列和接收队列的组合。且在RDMA中,通信的基本单位是QP,对于每个节点来说,每个进程可以使用若干QP。每个节点的QP都有一个唯一的编号,称为QPN。
- CQ :Complete Queue。完成队列,通常存放一个任务的完成报告。其中元素的名字是CQE,和WQE是一组相反的概念。如果说WQE是软件下达给硬件的,那么CQE则是硬件反馈给软件的。
基本过程
基本的工作流程如下图所示。下图说明了可靠服务类型的交互流程,因此第五步是由接收端返回ACK给发送端。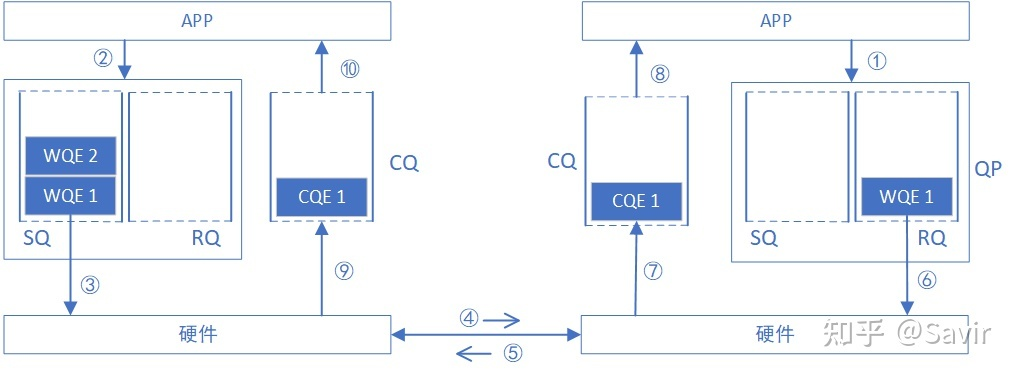
而RQ是一个被动的过程,只有收到Send报文的时候,硬件才会消耗RQ中的WQE。
因此在APP眼中,又将引入以下两个概念。 - WC:Work Complete。就是CQE在用户APP中的映射。
- WR:Work Request。就是WQE在用户APP中的映射。
代码层面
post_send的实现
先看到内核中的发送函数ib_post_send(),最终也是调用与设备相关的函数post_send。而ops.post_send是ops结构体中的一个函数指针,ops是ib_device_ops类型的。看结构应该是定义了从设备到具体硬件的过程。通过函数指针的形式,引用到真正的post_send实现之中去。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15static inline int ib_post_send(struct ib_qp *qp,
const struct ib_send_wr *send_wr,
const struct ib_send_wr **bad_send_wr)
{
const struct ib_send_wr *dummy;
return qp->device->ops.post_send(qp, send_wr, bad_send_wr ? : &dummy);
}post_send函数是在指定的QP上进行操作的。而QP又与device绑定,而与设备相关的操作device_ops又与device绑定。1
2
3
4
5
6
7
8
9
10struct ib_device_ops {
....
int (*post_send)(struct ib_qp *qp, const struct ib_send_wr *send_wr,
const struct ib_send_wr **bad_send_wr);
int (*post_recv)(struct ib_qp *qp, const struct ib_recv_wr *recv_wr,
const struct ib_recv_wr **bad_recv_wr);
....
那么post_send具体的实现,又是在哪步被挂上的呢?
看到Linux内核源码中的drivers/infiniband/hw/mlx5/main.c文件中,存在以下代码。可以看到在此处绑定了mlx5_ib_dev_ops的具体函数。那么接下去就有两个探索方向,一个是向下到硬件实现去,另外一个则是向上探索mlx5_ib_dev_ops在何处被启用。1
2
3
4
5
6
7static const struct ib_device_ops mlx5_ib_dev_ops = {
...
.post_recv = mlx5_ib_post_recv_nodrain,
.post_send = mlx5_ib_post_send_nodrain,
...
}向下探索
继续跳转代码进入到mlx5_ib_post_send的具体实现之中,按照章节RDMA发送基本过程中所说,硬件设备会提取RQ中的一个WR(WQE),根据WR的内容处理消息。在这里还没有仔细阅读。1
2
3
4
5
6
7
8
9
10
11static inline int mlx5_ib_post_send_nodrain(struct ib_qp *ibqp,
const struct ib_send_wr *wr,
const struct ib_send_wr **bad_wr)
{
return mlx5_ib_post_send(ibqp, wr, bad_wr, false);
}向上探索
查找mlx5_ib_dev_ops的定义,可以看到在函数mlx5_ib_stage_caps_init中绑定了设备操作与设备。查找mlx5_ib_stage_caps_init在何时被调用。找到mlx5_ib_stage_caps_init在struct mlx5_ib_profile中被定义。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15static int mlx5_ib_stage_caps_init(struct mlx5_ib_dev *dev) {
// .... 省略
if (MLX5_CAP_DEV_MEM(mdev, memic) ||
MLX5_CAP_GEN_64(dev->mdev, general_obj_types) &
MLX5_GENERAL_OBJ_TYPES_CAP_SW_ICM)
ib_set_device_ops(&dev->ib_dev, &mlx5_ib_dev_dm_ops);
ib_set_device_ops(&dev->ib_dev, &mlx5_ib_dev_ops);
// .... 省略
}而pf_profile在mlx5r_probe函数被引用。而该函数形成了mlx5 driver的一部分。1
2
3
4
5
6
7
8
9static const struct mlx5_ib_profile pf_profile = {
// .... 省略
STAGE_CREATE(MLX5_IB_STAGE_CAPS,
mlx5_ib_stage_caps_init,
mlx5_ib_stage_caps_cleanup),
// .... 省略
}该驱动在mlx5_ib_init函数中被使用。该函数通过module_init被加载。module_init是一个宏,用于在载入内核的模块。1
2
3
4
5
6
7
8
9
10
11static struct auxiliary_driver mlx5r_driver = {
.name = "rdma",
.probe = mlx5r_probe,
.remove = mlx5r_remove,
.id_table = mlx5r_id_table,
};如果将前文所述内容反过来看,就是一个完整的Linux Kernel绑定Verbs API和具体的驱动的过程。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71module_init(mlx5_ib_init);
static int __init mlx5_ib_init(void)
{
int ret;
xlt_emergency_page = (void *)__get_free_page(GFP_KERNEL);
if (!xlt_emergency_page)
return -ENOMEM;
mlx5_ib_event_wq = alloc_ordered_workqueue("mlx5_ib_event_wq", 0);
if (!mlx5_ib_event_wq) {
free_page((unsigned long)xlt_emergency_page);
return -ENOMEM;
}
mlx5_ib_odp_init();
ret = mlx5r_rep_init();
if (ret)
goto rep_err;
ret = auxiliary_driver_register(&mlx5r_mp_driver);
if (ret)
goto mp_err;
ret = auxiliary_driver_register(&mlx5r_driver);
if (ret)
goto drv_err;
return 0;
drv_err:
auxiliary_driver_unregister(&mlx5r_mp_driver);
mp_err:
mlx5r_rep_cleanup();
rep_err:
destroy_workqueue(mlx5_ib_event_wq);
free_page((unsigned long)xlt_emergency_page);
return ret;
}WR的实现
而send_wr的定义如下。ib_send_wr在内核Verbs API中是最基本的WR数据结构,随之衍生的WR数据结构还有1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29struct ib_send_wr {
struct ib_send_wr *next;
union {
u64 wr_id;
struct ib_cqe *wr_cqe;
};
struct ib_sge *sg_list;
int num_sge;
enum ib_wr_opcode opcode;
int send_flags;
union {
__be32 imm_data;
u32 invalidate_rkey;
} ex;
};SGE
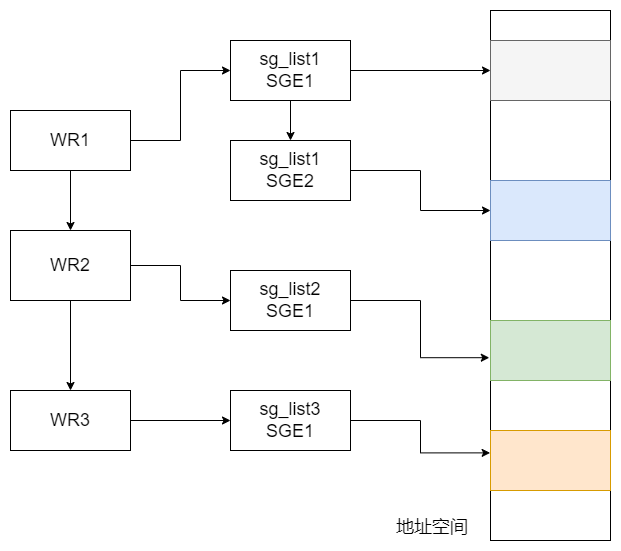
可以在ib_send_wr中看到以下的定义。sg_list用来存放SGE元素,每一个SG是一个数据段。SG(Scatter/Gather),从名字中可以看出,该数据段的用处就是聚合分散的地址空间。1
2
3struct ib_sge *sg_list;
int num_sge;字段说明如下所示。1
2
3
4
5
6
7
8
9struct ib_sge {
u64 addr;
u32 length;
u32 lkey;
}; - addr : 数据段所在的虚拟内存的起始地址。
- length : 数据段长度。
- lkey : 数据段对应的lkey。
RECV过程中的WR行为
本来是想在post_send中寻找使用SGE聚合消息,然后组装成数据帧的过程。但是没有发现相关内容。
但是在post_recv中却发现了相关内容。scat是mlx5_wqe_data_seg类型的消息,根据RDMA接收消息的过程进行合理推测。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19int mlx5_ib_post_recv(struct ib_qp *ibqp, const struct ib_recv_wr *wr,
const struct ib_recv_wr **bad_wr, bool drain)
{
// 省略
if (qp->flags_en & MLX5_QP_FLAG_SIGNATURE)
scat++;
// 遍历WR
// 此处的WR是ib_recv_wr
for (i = 0; i < wr->num_sge; i++)
set_data_ptr_seg(scat + i, wr->sg_list + i);
// 省略
} - 当接收端设备接收到消息后,调用post_recv回调函数。
- 此时post_recv回调函数消费一个WR,根据WR中的SGE配置内存区域。聚合成scat。
- 根据scat的地址信息对数据进行复制。
总结
- 分析了Linux RDMA InfiniBand实现,从上到底层,驱动的初始化过程。