作者:Solal Pirelli and George Candea,洛桑联邦理工学院
开源代码:https://github.com/dslab-epfl/tinynf
论文链接:https://www.usenix.org/conference/osdi20/presentation/pirelli
背景
软件网络功能的出现要求在堆栈的每一层都提供更强大的正确性保证和更高的性能。当前的网络堆栈以简单性换取性能和灵活性,尤其是在它们的驱动程序模型中。
作者展示了性能和简单性可以共存,以牺牲一些灵活性为代价,使用针对网络功能量身定制的新 NIC 驱动程序模型。
作者用 550 行代码实现了 Intel 82599 网卡的驱动程序。通过仅用文中的驱动程序替换最先进的驱动程序,整个软件堆栈的形式验证完成时间减少了 7 倍,而经过验证的函数的吞吐量提高了 160%。由于其低可变性和资源使用,文中的驱动程序在实际工作负载上也击败了尚未正式验证的驱动程序的吞吐量。
NIC
接收数据包:
- CPU 将描述符提供给 NIC,指示数据包在内存中的位置
- 接收数据包后,NIC 就会返回描述符
- 描述符元数据由CPU设定
发送数据包:
- CPU 将描述符提供给 NIC,指示数据包存放在内存中的位置
- 传输数据包后,NIC 就会返回描述符
- 描述符元数据由NIC设定
NIC队列: descriptor ring+配置信息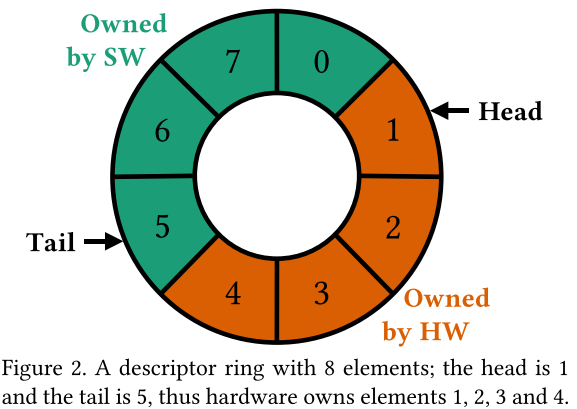
原有驱动模型
在 DPDK 等现代框架中,基于重复使用一组固定的数据包缓冲区,以避免内存分配的开销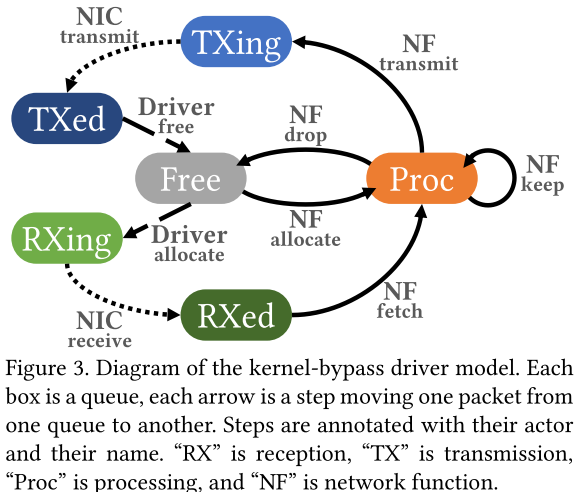
其中整个系统是一组先进先出的缓冲队列。
组成:网卡NIC + 驱动程序Driver + 网络功能NF
流程:
- 在初始状态下,所有缓冲区都处于“Free”状态,这表示缓冲池中未使用的缓冲区。
- 接收数据包:
- 从池中“分配”缓冲区并将它们提供给 NIC 进行接收
- 分配的缓冲区处于“receiving”状态
- 这种“分配”是指从缓冲池中获取缓冲区,而不是创建新缓冲区
- 从网络获取数据,NIC将接收缓冲区转换为“received”状态
- NF运行轮询循环以将缓冲区移动到“processing”步骤
- 从池中“分配”缓冲区并将它们提供给 NIC 进行接收
- 发送数据包:
- NF传输缓冲区
- NIC 将缓冲区内容发送到网络,并将缓冲区移动到“transmitted”状态
- 驱动程序将标明要进行空闲的传输缓冲区移回“free”状态
- NF对于缓冲区的管理:
- 当剩余的空闲缓冲区太少时,NF可以选择保留缓冲区供以后使用
- 可以直接将缓冲区丢进空闲缓冲池
- 可以直接从缓冲池中分配缓冲区
缺点:
- 参与者不能从外部插入缓冲区
- 是一个封闭系统
- 缓冲区分配和释放是昂贵的
- 操作系统对相关缓冲区的的更改,网卡无法感知
- 缓冲区分配和释放是昂贵的
- 是一个封闭系统
- 驱动和NF对于缓冲区的分配和释放路径复杂化
- NF的灵活性(有时会保留缓冲区)有时是不需要的,造成了简单性换灵活性的问题
优点:
- 为NF提高了灵活性
- 可以将缓冲区放在一边,重新组合来自协议栈的消息
- 可以进行并发操作
- NF可以从多个NIC接收和传输数据包
论文中的驱动模型
- 专为无需灵活性、而需简单性而设计
- 人话:包不会出现乱序的情况,NF不用保留缓冲池
- 核心:删除缓冲池
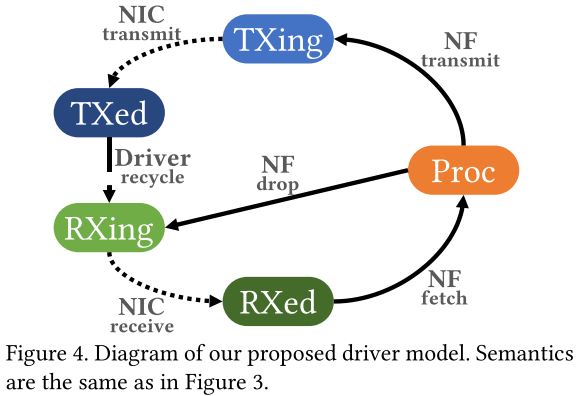
- 驱动程序将传输缓冲区直接移动到接收队列
- NF所拥有的发送缓冲区可以直接drop,成为接收缓冲区
驱动的工作:
- 当NF请求数据包时,将缓冲区从“received”队列移动到“processing”队列
- 当NF发送或丢弃数据包时,将缓冲区从“processing”队列移动到“transmitting”队列传输
- 丢弃包与原有方式不同的是:与传送数据包进行了统一,丢弃时发送metadata为0的缓冲区,走发送数据包相同路线
- 将缓冲区从“transmitted”队列回收到“receiving”队列,以确保“接收”队列永远不会为空(定时收回)
特点:
- 支持多个输出(发送数据包)
- 建立多个传输ring
- 当一个ring指向该缓冲区的描述符,其余ring的相应位置置为空
- 建立多个传输ring
- 可以同时处理多个输入(接收数据包)
- 每个输入关联一个接收队列,一个处理队列
- 支持并行操作
缺点:
- NF无法保留缓冲区供以后使用
- 如对于TCP协议的包乱序,无法修复
TinyNF
Tiny Network Function
一次处理一个缓冲区
- 处理队列中始终最多有一个缓冲区
完全在用户模式下运行,没有内核依赖
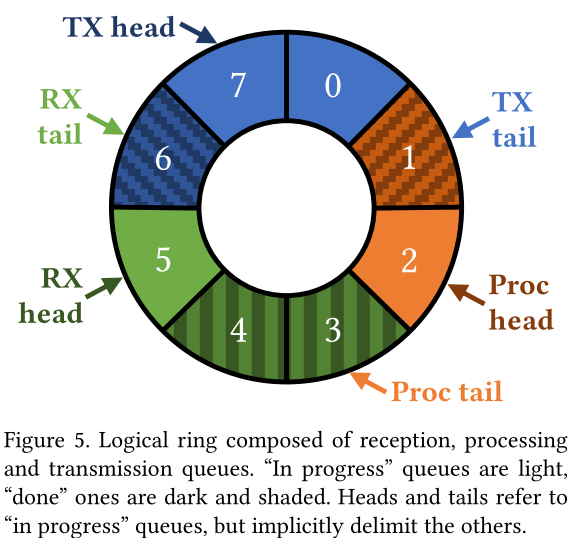
灵感来源:实际的定界符比理论的定界符少“transmitted”头和尾分别是“receiving”尾和“transmitting”头
“received”头和尾是“processing”尾和“receiving”头
虽然不存在的“processed”队列,但其头部和尾部分别是“transmitting”尾部和“processing”头部
“processing”尾部不需要跟踪
- 由于一次一个数据包的约束,它总是在头部之前或等于头部的一个缓冲区
TinyNF只需要更新receive(receiving、received)和transmit(transmitted、transmitting)尾部
- 在NIC 寄存器中
- 每隔几次传输完成一次更新
调度策略:最小化软件和硬件之间的通信量,改善整体延迟并减少了用于元数据的 PCIe 吞吐量
- 请求NIC更新传输的尾部并检查此类更新以回收缓冲区(64个数据包进行一次该操作)
- 请求是用传输元数据中的一个位(bitmap)发出的
- 检查是通过读取 NIC 通过 DMA 写入 RAM 的值来进行的
- 更新传输尾部:
- 每隔几个传输的数据包(或有空闲时间时)更新一次传输尾部
- 请求NIC更新传输的尾部并检查此类更新以回收缓冲区(64个数据包进行一次该操作)
实验
- tinyNF在代码数量和代码复杂度方面更较少,开发人员更容易进行网络功能的验证
- TinyNF优于完整优化的DPDK
- 采用traffic policer流量监管方式:
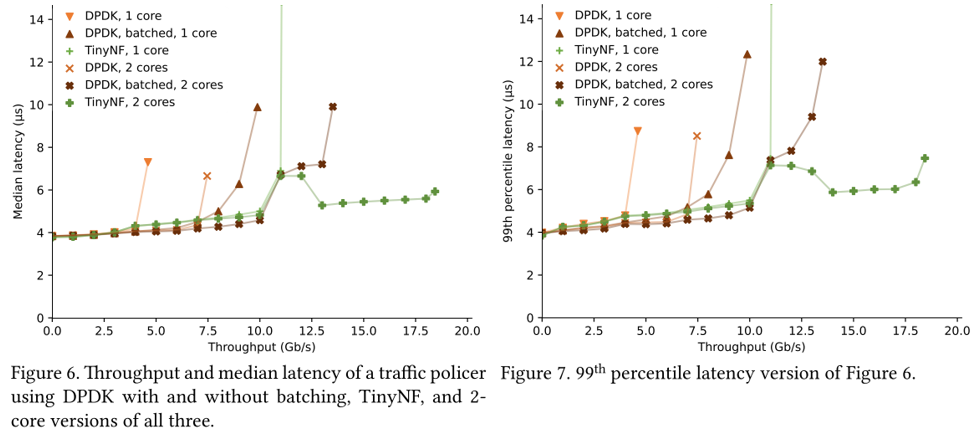
- unbatched DPDK:Vigor使用的简单版本
- batched DPDK:DPDK的标准方式
- 采用traffic policer流量监管方式:
- 支持很多网络功能:负载平衡、DPI、NAT、防火墙、隧道、多播、BRAS、监控、DDoS防范、IP代理、拥塞控制、IDS、IPS、以太网桥接器、ARP客户端和服务器、DNS代理、统计收集器、交通监管器和谷歌的Maglev负载平衡器
实验收获:作者在实验对比时多次采用自动化验证工具验证。他认为采用自动化验证工具验证,更容易发现系统中存在的优秀结果,并可以移除不需要的结构,提升系统性能