作者:Yuhong Zhong,Haoyu Li等,哥伦比亚大学与谷歌合作完成
会议:OSDI2022
开源代码:https://github.com/xrp-project/XRP
介绍
随着微秒级 NVMe 存储设备的出现,Linux 内核存储堆栈开销占比变高,访问时间几乎翻倍。
作者依靠 BPF让应用程序将简单功能卸载到 Linux 内核。
- 与内核旁路类似,通过将应用程序逻辑深入内核堆栈,BPF 可以消除与内核用户交互和相关上下文切换相关的开销。
- 与内核旁路不同,BPF是OS支持的机制,保证了隔离性,不会因为轮询忙等导致core利用率低下,允许大量线程或进程共享同一个core,整体利用率更好。
但是使用 BPF 来加速存储会带来几个独特的挑战。I/O resubmission可能会延迟较大。
I/O resubmission: I/O 的重新提交,应用当前请求需要进行多次I/O查找。同步与其他并发应用程序级操作或需要多个函数调用来遍历大型磁盘数据结构。
作者设计并实施了 XRP(eXpress Resubmission Path),这是一种使用 Linux eBPF 的高性能存储数据路径。XRP 在 NVMe 驱动程序的中断处理程序中使用了一个挂钩,绕过了内核的块、文件系统和系统调用层。这允许 XRP 在每个 I/O 完成时直接从 NVMe 驱动程序触发 BPF 功能,从而能够快速重新提交遍历存储设备上其他块的 I/O。同时为了保留文件系统语义,XRP 将少量内核状态传播到其NVMe 驱动程序
作者在文中做出的贡献:
- 新数据路径。 XRP 是第一个支持使用 BPF 将存储功能卸载到内核的数据路径。
- 性能。与普通系统调用相比,XRP 将 B 树查找的吞吐量提高了 2.5 倍。
- 利用性。 XRP提供接近内核旁路的延迟,但与内核旁路不同的是,它允许内核被相同的线程和进程有效地共享。
- 可扩展性。 XRP支持不同的存储用例,包括不同的数据结构和存储操作(例如,索引遍历、范围查询、聚合)。
背景
软件开销成为存储瓶颈
作者展示了最新一代设备软件开销约占一半每个读取请求的延迟。随着存储设备变得更快,内核的相对开销只会变得更糟。
同时,文中测试了发出随机512 B读取时在不同存储层中花费的时间,实验表明,最昂贵的层是文件系统(ext4),其次是块层(bio)和内核用户交互,总软件开销占平均延迟的 48.6%。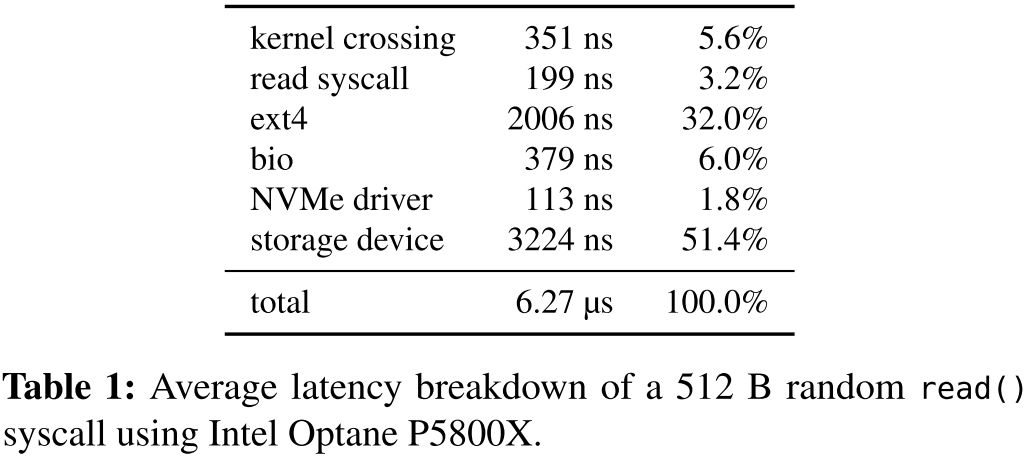
为什么不直接绕过内核呢?
SPDK是完全绕过内核,应用直接和设备通信,只留下向 NVMe 驱动程序发布请求的成本和设备的延迟。然而:
- 绕过内核需要用户构建自己的用户空间文件系统。
- 应用程序必须直接轮询设备完成队列以获得高性能,需要占用一个core。导致严重的利用率不足和 CPU 浪费。
- 当多个轮询线程共享同一个处理器时,它们之间的 CPU 争用加上缺乏同步会导致所有轮询线程的尾部延迟降低并显着降低整体吞吐量。
BPF入门知识
BPF参考博客
BPF(Berkeley Packet Filter)是一个接口,允许用户卸载由内核执行的简单功能。
Linux 的 BPF 框架称为eBPF(extended BPF)。 Linux eBPF 通常用于过滤数据包(例如 TCPdump)、负载平衡和数据包转发、跟踪、数据包转向、网络调度和网络安全检查。
在数据查找需要 I/O请求的情况下, BPF可以是用于避免内核与用户空间之间的数据移动的机制,所述I/O请求生成应用不直接需要的中间数据。例如要遍历 B 树索引,每个级别的查找都会遍历内核的整个存储堆栈,一旦应用程序获得指向树中下一个子节点的指针,它就会被丢弃。每个中间指针查找都可以由 BPF 函数执行,而不是来自用户空间的一系列系统调用,该函数将解析 B 树节点以找到指向相关子节点的指针。然后内核将提交I/O以获取下一个节点。 链接一系列这样的 BPF 函数可以避免遍历内核层和将数据移动到用户空间的成本。
BPF函数可以放置在内核的任何层。下图显示了用户系统调用和采用BPF挂钩的I/O路径。
- 橙线:左半部分是应用第一次发出IO请求,右半部分是所有I/O请求完成后对应用的响应。
- 蓝线:I/O resubmission时,采用系统调用的方式的I/O路径。
- 蓝线:I/O resubmission时,采用BPF挂钩的方式的I/O路径。
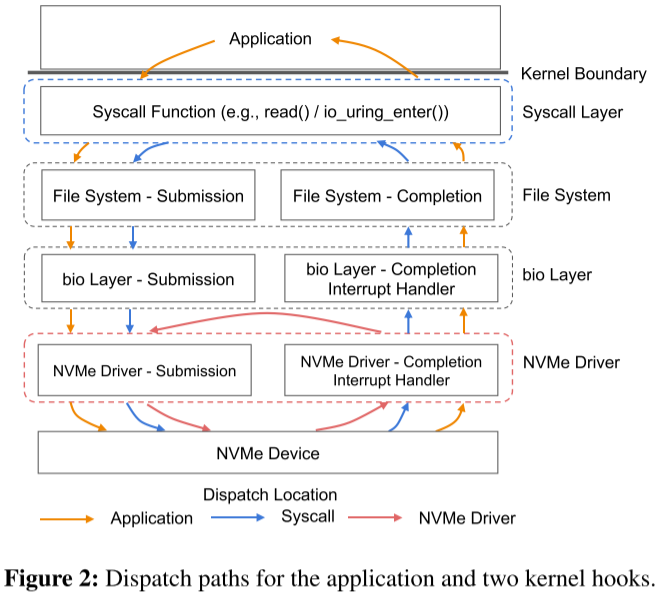
在内核中的任何位置放置一个eBPF钩子可以将吞吐量提高1.2–2.5倍。
然而,将 I/O 调度推到尽可能靠近存储设备的位置可以显着提高性能。因此,XRP 的I/O resubmission挂钩放在 NVMe 驱动程序中。
io_uring: io_uring 是一个新的 Linux 系统调用框架,它允许进程提交成批的异步 I/O 请求,从而分摊用户-内核上下文。但是,每个使用 io_uring 提交的 I/O 仍会通过表 1 中显示的所有层,因此每个单独的 I/O 仍会产生完整的存储堆栈开销。事实上,BPF I/O 重新提交在很大程度上是对 io_uring 的补充:io_uring 可以高效地提交批次的 I/O,这些 I/O 会触发内核中由 BPF 管理的不同 I/O 链
设计挑战及原则
I/O重新提交会靠近NVMe中断处理程序。 然而从NVMe中断处理序中执行时会缺乏文件系统层的上下文,引入了两个主要挑战:
- 挑战1:解决翻译和安全问题。 NVMe驱动程序无法访问文件系统元数据。 比如在索引遍历的示例中,XRP发布了一个读取I/O到特定块,并执行一个BPF函数,该函数将提取它想要查询的下一个块的偏移量。 然而这种偏移对NVMe层毫无意义,因为它无法判断偏移对应于哪个物理块,而无法访问文件的元数据和范围。
- 挑战2:并发和缓存。从文件系统发出的写入只会反映在页面缓存中,这对 XRP 是不可见的。此外,与读取请求同时发出的任何修改数据结构布局的写入(例如,修改指向下一个块的指针)都可能导致 XRP 意外获取错误数据。这两个问题都可以通过锁来解决,但是从 NVMe 中断处理程序中访问锁可能代价高昂。
设计原则:
- 一次一个文件。我们最初限制 XRP 仅在单个文件上发布链式重新提交。 这大大简化了地址转换和访问控制,并最小化了我们需要向下推送到NVMe驱动程序的元数据(元数据摘要,后续讲到)。
- 稳定的数据结构。XRP针对数据结构,其布局(即指针)在长时间内(即秒或更长时间)保持不变。 此类数据结构包括在许多流行的商业存储引擎中使用的指数,如RocksDB、LevelDB、TokuDB和WiredTiger。 由于在NVMe层中实现锁的成本较高,我们最初也不计划支持在数据结构的遍历或迭代期间需要锁的操作。
- 用户管理的缓存。 XRP和页面缓存没有接口,因此如果块 缓冲在内核页面缓存中,则 XRP 函数无法安全地并发运行。这种约束是可以接受的,因为流行的存储引擎通常会实现自己的用户空间缓存;通常这样做是为了微调缓存和预取策略,并以对应用程序有意义的方式缓存数据(例如,缓存键值对或数据库行而不是物理块)。
- 慢路径回退。 XRP 是尽力而为的;如果由于某种原因遍历失败(例如,范围映射变得陈旧),应用程序必须重试或回退到使用用户空间系统调用分派 I/O 请求。
XRP 设计与实现
I/O resubmission
XRP 的核心通过I/O重新提交增强了 NVMe 中断处理程序,该逻辑由 BPF的hook、文件系统转换步骤以及在新物理偏移上构建和重新提交下一个 NVMe 请求组成。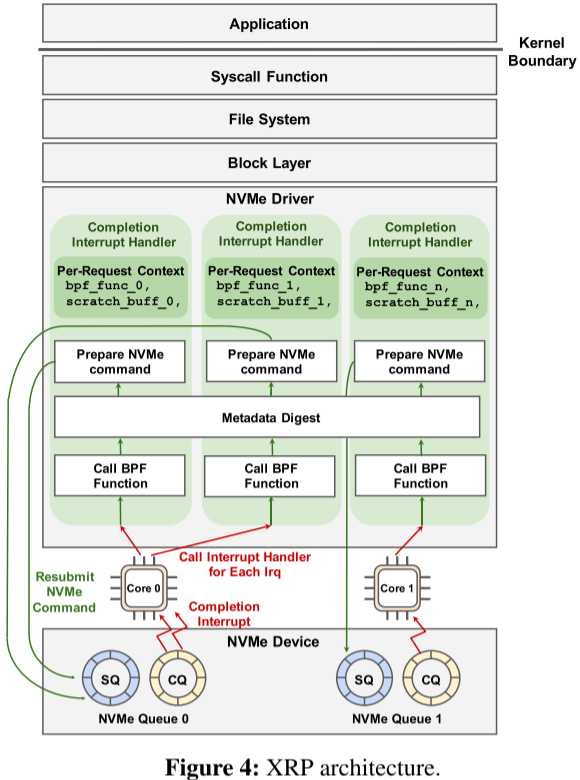
当 NVMe 请求完成时,设备会生成一个中断,导致内核上下文切换到中断处理程序。对于在中断上下文中完成的每个 NVMe 请求,XRP 调用其关联的 BPF 函数(图中的 bpf_func_0),其指针存储在内核 I/O 请求结构(即 struct bio)的一个字段中。在调用 BPF 函数后,XRP 调用元数据摘要,这通常是文件系统状态的摘要,使 XRP 能够转换下一次重新提交的逻辑地址。最后,XRP 通过设置 NVMe 请求中的相应字段来准备下一个 NVMe 命令重新提交,并将请求附加到该核心的 NVMe 提交队列 (SQ)。
对于特定的 NVMe 请求,重新提交逻辑将被调用多次(由在 NVMe 请求中注册的特定 BPF 函数确定)。例如,对于树状数据结构的遍历,BPF 函数会重新提交分支节点的 I/O 请求,并在找到叶节点时结束重新提交。
BPF 函数上下文是每个请求的,而元数据摘要在所有内核的中断处理程序的所有调用之间共享。对元数据摘要的安全并发访问依赖于读取-拷贝-更新机制(RCU,Linux 内核中的同步机制,对于共享数据,想要修改会先创建副本修改)
BPF Hook
XRP 引入了一种新的BPF类型(BPF_PROG_TYPE_XRP),任何与该标签匹配的 BPF 函数都可以从钩子中调用。
BPF_PROG_TYPE_XRP 程序需要一个包含五个字段的上下文
1 | struct bpf_xrp { |
为了支持扇出(指该模块直接调用的下级模块的个数)的数据结构,可以提供多个 next_addr 值。默认情况下,我们将扇出限制为 16。
scratch 是用户和 BPF 函数私有的暂存空间。它可用于将参数从用户传递到 BPF 函数。此外,BPF 函数可以使用它来存储 I/O 重新提交之间的中间数据,并将数据返回给用户。
每个 BPF 上下文对于一个 NVMe 请求都是私有的,因此在使用 BPF 上下文状态时不需要锁定。让用户提供临时缓冲区(而不是使用 BPF 映射)避免了必须调用 bpf_map_lookup_elem 来访问临时缓冲区的进程和函数的开销。
BPF验证器
BPF 验证器通过跟踪存储在每个寄存器中的值的语义来确保内存安全。
元数据摘要
在传统的存储堆栈中,磁盘数据结构中的逻辑块偏移量由文件系统转换,以便识别要读取的下一个物理块。此转换步骤还强制执行访问控制和安全性,防止读取未映射到打开文件的区域。在 XRP 中,查找的下一个逻辑地址由 BPF 调用后的 next_addr 字段给出。然而中断处理程序没有文件的概念并且不执行物理地址转换。
为了解决这个问题,作者实现了元数据摘要,这是文件系统和中断处理程序之间的一个薄接口,它允许文件系统与中断处理程序共享其逻辑到物理块的映射,从而实现基于 eBPF 的安全磁盘重新提交。元数据摘要由两个函数组成:
1 | void update_mapping(struct inode *inode); |
- 更新函数:在文件系统中调用,更新逻辑到物理映射。
- 查找函数:中断处理程序中调用;它返回给定偏移量和长度的映射。还通过防止 BPF 函数请求重新提交打开文件之外的块来强制执行访问控制。打开文件的 inode 地址被传递给中断处理程序以查询元数据摘要。
这两个功能是特定于每个文件系统的,即使对于特定的文件系统,也可能有多种方法来实现元数据摘要。例如,在 ext4 实现中,元数据摘要包含扩展状态树的缓存版本,它存储物理到逻辑块映射。该缓存树由接口的更新和查找功能访问,并使用读取-复制-更新(RCU)进行并发控制。
重新提交 NVMe 请求
查找物理块偏移量后,XRP 准备下一个 NVMe 请求。因为这个逻辑发生在中断处理程序中,为了避免准备 NVMe 请求所需的(缓慢的)kmalloc 调用,XRP 重用了刚刚完成请求的现有 NVMe 请求结构(即 struct nvme_command)。 XRP 只是将现有 NVMe 请求的物理扇区和块地址更新为从映射查找中导出的新偏移量。重用 NVMe 请求结构以立即重新提交是安全的,因为用户空间和 XRP BPF 程序都无法访问原始 NVMe 请求结构。
虽然 struct bpf_xrp 支持最大扇出 16,但在当前实现中,重新提交的 I/O 请求只能获取与初始 NVMe 请求一样多的物理段,因为延用初始NVMe的请求。
同步限制
BPF 目前只支持有限的自旋锁进行同步。验证器一次只允许 BPF 程序获取一个锁,并且在返回之前必须释放锁。
此外,用户空间应用程序无法直接访问这些 BPF 自旋锁。相反,他们必须调用 bpf() 系统调用;系统调用可以读取或写入受锁保护的结构,同时在该操作期间持有锁。因此,需要在多个读写之间进行同步的复杂修改无法在用户空间中完成。
用户可以使用 BPF 原子操作实现自定义自旋锁。这允许 BPF 函数和用户空间程序直接获取任何自旋锁。但是,终止约束禁止 BPF 函数自旋以无限等待自旋锁。另一个同步选项是 RCU。由于 XRP BPF 程序在 NVMe 中断处理程序中运行,无法被抢占,事实上它们已经在 RCU 读取端临界区中。
与 Linux 调度程序交互
进程调度器:当多个进程共享同一个核心时,微秒级低延迟存储设备会干扰 Linux 的 CFS(完全公平调度算法),即使所有 I/O 都是从用户空间发出的。我们实验验证了在使用速度较慢的存储设备时不会发生这种情况,该设备生成中断的频率要低得多。虽然 XRP 通过生成中断链加剧了这个问题,但这个问题并不是 eBPF 特有的,也可能是由网络驱动的中断引起的。我们把这个问题留给以后的工作。
I/O 调度程序: XRP 绕过了位于块层的 Linux 的 I/O 调度程序。但是,noop调度程序已经是 NVMe 设备的默认 I/O 调度程序,如果需要公平性,NVMe 标准支持在硬件队列上进行仲裁
Evaluation
作者采用XRP修改了两种键值存储应用程序:
- BPF-KV:作者构建,一种基于 B+ 树的键值存储,专门为支持 BPF 功能而设计
- WiredTiger:日志结构合并树,用作 MongoDB 的存储引擎之一。
在实验中,作者回答以下问题:
- 使用 BPF 进行存储的开销情况
- XRP 如何扩展到多线程
- XRP 支持哪些类型的操作
- XRP 能否加速现实世界的键值存储
延迟:可以看出,线程数较少时,XRP的延迟略高于SPDK。但是,XRP 无需借助轮询即可实现这一点。这意味着与 SPDK 不同,XRP的进程可以继续高效地使用 CPU 内核来完成其他工作。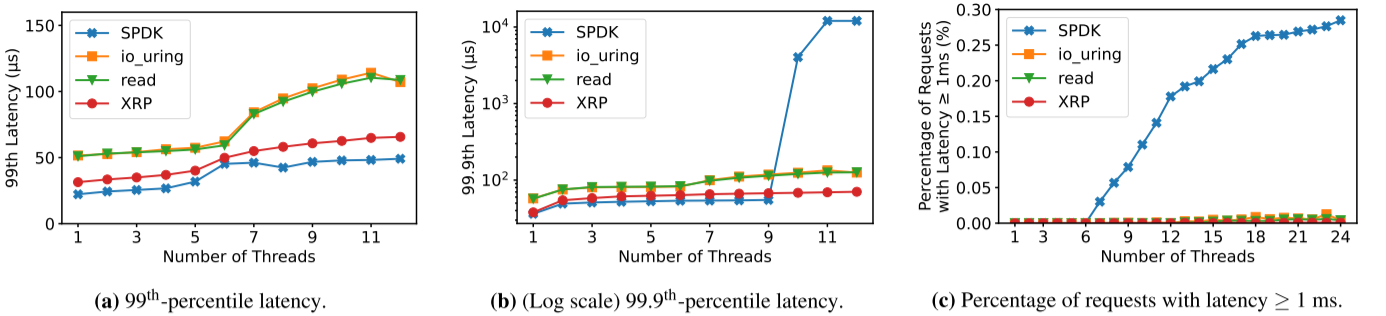
吞吐量:与 SPDK 相比,线程数越高,XRP 吞吐量越高。但是线程数较少时会弱于SPDK。
多线程:线程数少于核数时,SPDK与XRP类似。超过时,SPDK性能急剧下降。
范围请求:与read()系统调用对比,XRP的延迟较低,吞吐量较高。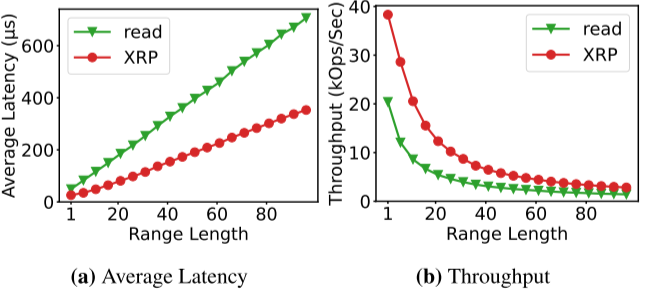
WiredTiger有无对比:测评XRP是否能让现有的数据库受益。结果表明,与用pread ()来读取Btree页面baseline相比,XRP 将大多数工作负载持续加速高达 1.25 倍。但XRP在WiredTiger上的速度比在BPF-KV上的速度要低,因为WiredTiger的非I/O操作占用率较高。
Related Work
- 使用 BPF 加速 I/O:主要集中在网络和跟踪用例。其中XDP与 XRP 关系最密切,它通过在 NIC 驱动程序的 RX 路径中添加挂钩来加速网络 I/O。然后它为 eBPF 程序提供一个接口,用于过滤、重定向或反弹数据包。
- 内核旁路:为了减少内核在处理 I/O 时的开销,设计库和操作系统来让用户直接访问 I/O 设备。其中英特尔的 SPDK与XRP最相关。一般来说,允许用户直接访问 I/O 的缺点是应用程序必须直接轮询 I/O 以获得高性能。这意味着内核不能在进程之间共享,当 I/O 不是瓶颈时会导致严重的未充分利用。
- 近存储计算:有几种系统允许应用程序将其存储功能卸载到嵌入或连接到存储设备的处理器。这种方法的缺点是它需要专门的存储设备和/或专用硬件。
- 可扩展操作系统和库文件系统:可扩展操作系统允许通过用户定义的函数扩展内核功能。例如,客户端可以编写内核扩展,从磁盘读取和解压缩视频帧。另一种相关方法是库文件系统,例如 XN。与 XRP 类似,XN 允许用户空间库文件系统将不受信任的元数据转换功能加载到内核中,同时在不了解文件系统数据结构的情况下保证磁盘块保护。这些方法需要使用专用的操作系统和文件系统,而 XRP 与 Linux 及其标准文件系统兼容。
Conclusions and Future Work
BPF 有可能通过将计算移近设备来加速使用快速 NVMe 设备的应用程序。 XRP 允许应用程序编写可以重新提交相关存储请求的函数,以实现接近内核旁路的加速,同时保留操作系统集成的优势。除了快速查找之外,我们设想 XRP 可用于许多类型的功能,例如压缩、压缩和重复数据删除。
此外,未来的 XRP 可以开发为其他需要将计算移近存储的用例的通用接口,例如可编程存储设备和网络存储系统。例如,XRP 可以用作动态支持内核卸载以及将功能卸载到智能存储设备或 FPGA 的接口。我们计划探索的另一个方向是网络存储。 XRP 存储功能可以与 XDP 网络功能链接,以创建绕过内核网络和存储路径的数据路径。
思考
- 因为xrp进行存储加速不需要像SPDK那样占用一个core,所以像unikernel这种单核操作系统,可以尝试借鉴xrp的存储方式
- 在网络计算方面也可以借鉴xrp这种功能卸载方式,看看能否进行DPDK的优化